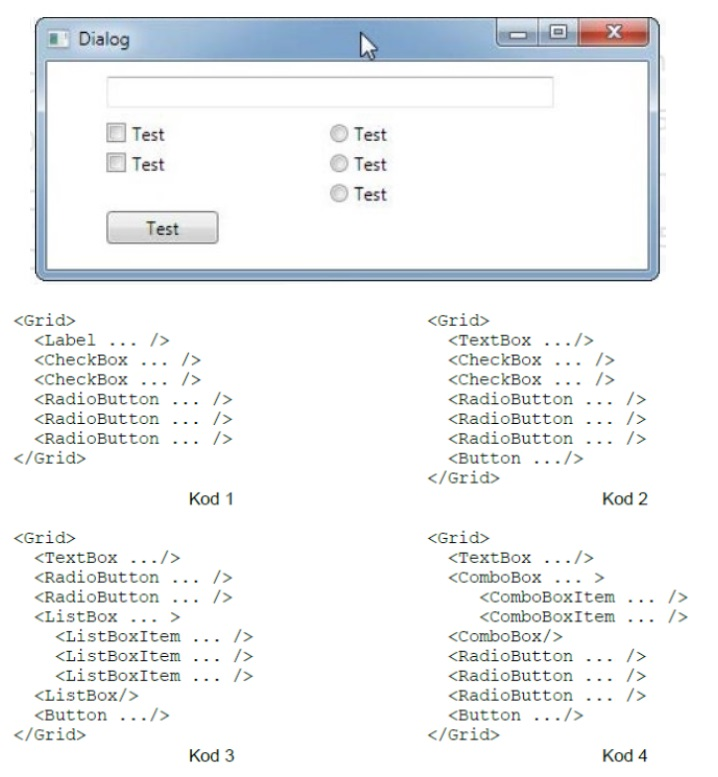
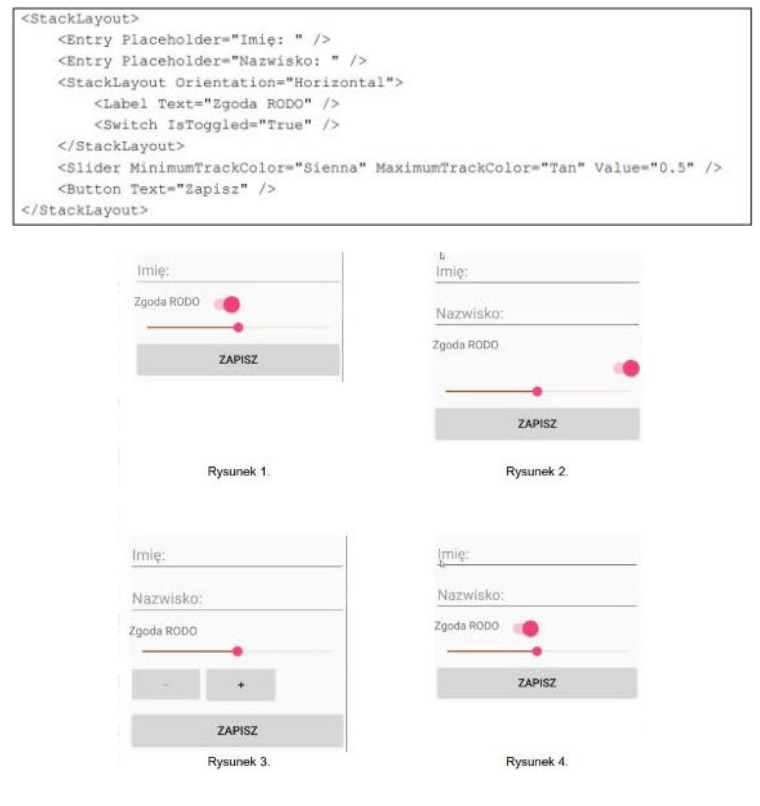
Pytanie 1
Jakie są różnice między typem łańcuchowym a typem znakowym?
A. Typ łańcuchowy obsługuje liczby całkowite, a znakowy liczby zmiennoprzecinkowe
B. Typ łańcuchowy przechowuje pojedyncze znaki, a znakowy długie ciągi znaków
C. Typ znakowy przechowuje dane logiczne, a łańcuchowy tekst
D. Typ znakowy przechowuje pojedyncze znaki, a łańcuchowy ciągi znaków
Typ znakowy (char) przechowuje pojedyncze znaki, natomiast typ łańcuchowy (string) przechowuje ciągi znaków. Różnica ta ma kluczowe znaczenie w programowaniu, ponieważ typ 'char' jest używany do operacji na pojedynczych literach, cyfrze lub symbolu, podczas gdy 'string' umożliwia przechowywanie i manipulowanie całymi wyrazami lub zdaniami. W wielu językach 'string' to bardziej złożona struktura danych, która zawiera tablicę znaków (array of characters), co pozwala na efektywną pracę z tekstem i budowanie interaktywnych aplikacji.