Pytanie 1
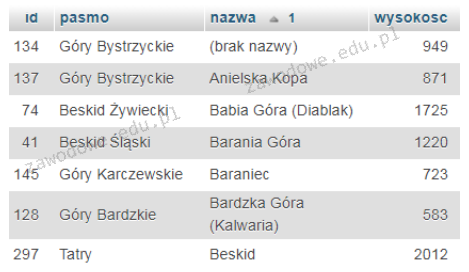
Który z poniższych kodów HTML najlepiej ilustruje opisaną tabelę? (Obramowanie tabeli oraz komórek zostało pominięte dla uproszczenia)

A. Odpowiedź B
B. Odpowiedź C
C. Odpowiedź A
D. Odpowiedź D
Odpowiedź B jest prawidłowa, ponieważ używa atrybutu rowspan do złączenia dwóch komórek w kolumnie. W przedstawionej tabeli nagłówek Telefony obejmuje dwie wartości w jednej kolumnie co jest dokładnie odwzorowane w kodzie HTML poprzez zastosowanie rowspan2 w komórce zawierającej Telefony. To podejście pozwala na logiczne i czytelne przedstawienie danych w tabeli co jest zgodne z dobrymi praktykami projektowania stron internetowych. Użycie rowspan w tabelach HTML jest powszechne gdy chcemy aby jedna komórka zajmowała miejsce większej liczby wierszy niż standardowa. Jest to przydatne w sytuacjach gdy dane muszą być grupowane pionowo co poprawia czytelność i strukturę prezentowanych informacji. Ponadto takie podejście pozwala na bardziej efektywne zarządzanie kodem HTML redukując potrzebę dodatkowego formatowania i zmniejsza złożoność dokumentu co jest zgodne z zasadami semantycznego HTML. Warto również pamiętać że użycie rowspan powinno być przemyślane aby zapewnić dostępność i poprawne wyświetlanie w różnych przeglądarkach i urządzeniach co jest kluczowe w nowoczesnym projektowaniu stron internetowych.