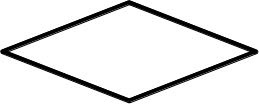
Ten blok w kształcie rombu to klasyczny symbol decyzji w schemacie blokowym algorytmu. Zgodnie z przyjętymi standardami notacji (np. ANSI/ISO dla diagramów przepływu), romb oznacza miejsce, w którym program musi coś sprawdzić i na podstawie wyniku tej kontroli wybrać jedną z gałęzi dalszego działania. Innymi słowy: następuje podjęcie decyzji na podstawie warunku logicznego, który zwykle daje odpowiedź typu TAK/NIE (TRUE/FALSE). W praktyce, w kodzie programistycznym taki romb odpowiada instrukcjom warunkowym, takim jak if, if...else, switch, operator trójargumentowy itp. Przykład: „jeśli użytkownik jest zalogowany, pokaż panel administracyjny, w przeciwnym razie przekieruj do logowania”. W schemacie blokowym byłby to właśnie romb z pytaniem „Użytkownik zalogowany?”. Z rombu wychodziłyby dwie strzałki: jedna podpisana „tak”, druga „nie”, prowadzące do różnych bloków akcji. Moim zdaniem warto wyrobić sobie nawyk automatycznego kojarzenia: romb = warunek = rozgałęzienie przepływu. Dzięki temu łatwiej później projektować algorytmy, niezależnie od języka programowania. W praktyce webowej też ma to duże znaczenie: np. sprawdzenie, czy dane z formularza są poprawne, czy użytkownik ma odpowiednie uprawnienia, czy plik istnieje na serwerze. Za każdym razem, gdy w głowie pojawia Ci się „jeśli… to… w przeciwnym razie…”, w schemacie blokowym powinien pojawić się właśnie taki romb, czyli blok podjęcia decyzji. To jest fundament logicznej struktury programu i jedna z podstawowych konstrukcji algorytmicznych.
Pytanie 2
Funkcja phpinfo() umożliwia
A. sprawdzenie wartości zmiennych zastosowanych w kodzie PHP
B. analizowanie kodu PHP w celu wykrycia błędów
C. uzyskanie danych o środowisku serwera, na którym działa PHP
D. rozpoczęcie wykonywania kodu w języku PHP
Funkcja phpinfo() jest niezwykle użytecznym narzędziem w PHP, które pozwala deweloperom na uzyskanie szczegółowych informacji o środowisku pracy serwera. Dzięki temu, można dowiedzieć się o zainstalowanych rozszerzeniach PHP, wersji PHP, ustawieniach konfiguracyjnych, a także o systemie operacyjnym, na którym działa serwer. Przykładowo, wywołanie phpinfo(); w skrypcie PHP zwraca stronę zawierającą różnorodne informacje, takie jak wartości zmiennych konfiguracyjnych (np. memory_limit, upload_max_filesize), co jest nieocenione podczas optymalizacji aplikacji oraz rozwiązywania problemów. Ponadto, korzystanie z phpinfo() jest zgodne z dobrymi praktykami w programowaniu, ponieważ pomaga zrozumieć, w jakim środowisku działa aplikacja, co jest kluczowe przy jej rozwijaniu i testowaniu. Deweloperzy często używają tej funkcji w fazie debugowania, aby upewnić się, że wszystkie wymagane rozszerzenia są aktywne i poprawnie skonfigurowane, co może zapobiec wielu problemom podczas wdrożenia aplikacji na produkcję.
Pytanie 3
W języku PHP zmienna $_GET jest zmienną
A. predefiniowaną, wykorzystywaną do zbierania wartości formularza po nagłówkach żądania HTTP (dane z formularza nie są widoczne w adresie)
B. predefiniowaną, używaną do przesyłania informacji do skryptów PHP za pośrednictwem adresu URL
C. zwykłą, utworzoną przez autora witryny
D. utworzoną przez autora strony, używaną do przesyłania danych z formularza przez adres URL
Odpowiedź jest poprawna, ponieważ zmienna $_GET w języku PHP jest predefiniowaną tablicą asocjacyjną, która służy do pobierania danych przekazanych przez metodę GET. Gdy użytkownik wysyła formularz z wykorzystaniem metody GET, wartości pól formularza są dołączane do adresu URL jako parametry zapytania. Na przykład, w adresie 'example.com/page.php?name=John&age=30', zmienna $_GET będzie zawierać wartości ['name' => 'John', 'age' => '30']. Dzięki temu skrypty PHP mogą uzyskiwać dostęp do tych danych i je przetwarzać. Używanie $_GET jest powszechną praktyką, szczególnie w przypadku, gdy dane nie są wrażliwe, ponieważ są widoczne w adresie URL. Ważne jest, aby pamiętać o bezpieczeństwie, stosując odpowiednie mechanizmy filtrowania i walidacji, aby uniknąć ataków, takich jak SQL Injection. Zastosowanie $_GET jest istotne w kontekście SPA (Single Page Applications), gdzie dane są często przesyłane na serwer w celu pobrania lub zaktualizowania zawartości strony bez przeładowania całej aplikacji.
Pytanie 4
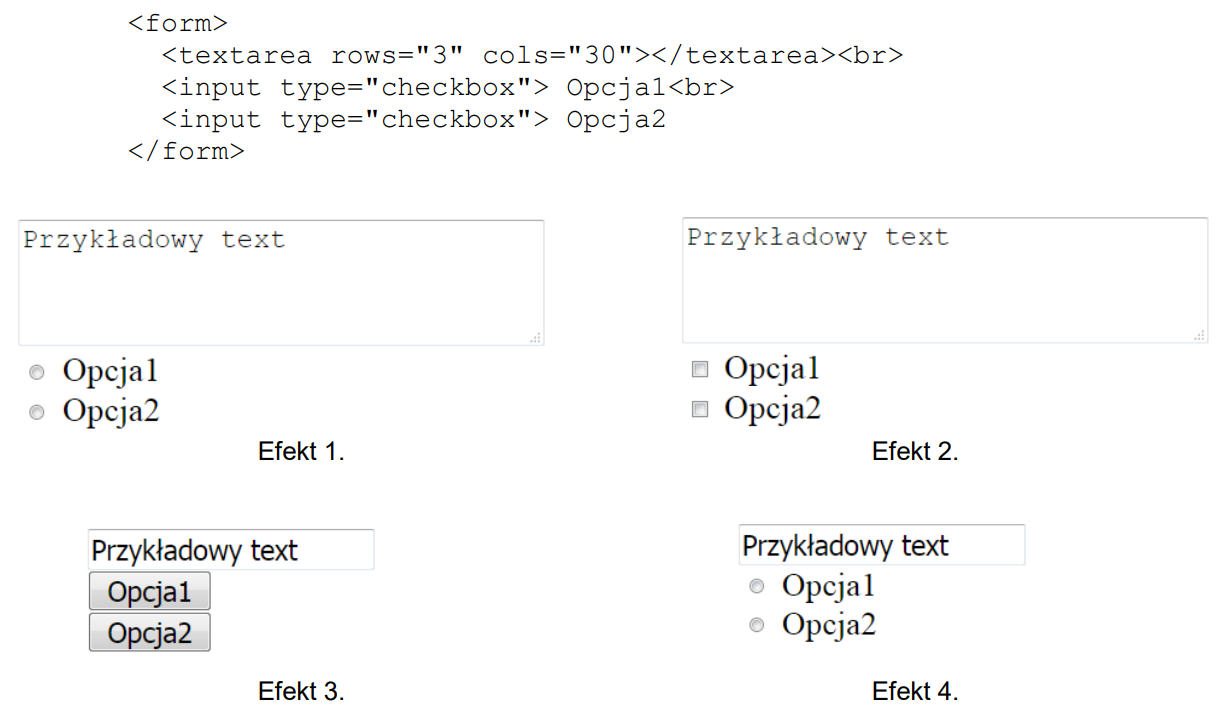
W języku HTML zapisano formularz. Który z efektów działania kodu będzie wyświetlony przez przeglądarkę zakładając, że w pierwsze pole użytkownik przeglądarki wpisał wartość "Przykładowy text"?
A. Efekt 2.
B. Efekt 3.
C. Efekt 4.
D. Efekt 1.
Dobra robota! Odpowiedź, którą wybrałeś, to Efekt 2. W formularzu HTML masz różne elementy, które służą do zbierania danych od użytkownika. Tutaj mamy pole tekstowe i dwa checkboxy. Jak wpiszesz 'Przykładowy text' w pole tekstowe i wyślesz formularz, to właśnie to się wyświetli w przeglądarce. Efekt 2 pokazuje, że pole tekstowe ma wpisany tekst i dwa niezaznaczone checkboxy. Dlatego to jest zgodne z tym, co zobaczysz w przeglądarce. A to oznacza, że Efekt 2 jest poprawną odpowiedzią. Właściwie to wszystko jest zgodne z tym, jak HTML działa, czyli jak powinny wyglądać i działać różne elementy formularza.
Pytanie 5
Jakie będzie efektem zastosowanego formatowania CSS dla nagłówka trzeciego stopnia
Odpowiedź, że tło będzie pomarańczowe, jest jak najbardziej trafna. W kodzie HTML użyto atrybutu "style" w tagu <h3>, który ma wyższy priorytet niż to, co jest zapisane w sekcji <style>. Wartość background-color to "orange", więc tło nagłówka trzeciego stopnia naprawdę będzie pomarańczowe. Znamy zasady kaskadowych arkuszy stylów, które mówią, że style bezpośrednio przypisane do elementów HTML mają pierwszeństwo. Kiedy chcemy, aby nagłówki miały różne kolory w zależności od tego, gdzie są użyte, inline styles są bardzo przydatne – zwłaszcza w prototypach. Ale z drugiej strony, z mojego doświadczenia, nadmiar inline styles może skomplikować późniejsze zarządzanie kodem, dlatego lepiej trzymać się klas CSS, żeby wszystko było bardziej uporządkowane.
Pytanie 6
Funkcji session_start() w PHP należy używać podczas realizacji
A. każdej strony, która wykorzystuje ciasteczka
B. przetwarzania formularzy
C. wielostronicowej strony internetowej, która wymaga dostępu do danych przy przechodzeniu między stronami
D. ładowania danych z zewnętrznych plików
Stosowanie funkcji session_start() w kontekście wczytywania danych z plików zewnętrznych jest nieadekwatne, ponieważ głównym celem tej funkcji jest zarządzanie sesjami użytkowników, a nie operacje na plikach. W przypadku wczytywania danych, zazwyczaj korzystamy z funkcji takich jak fopen(), fread() czy file_get_contents(), które są bezpośrednio przeznaczone do pracy z danymi przechowywanymi w plikach. Ponadto, wykorzystanie sesji w kontekście ciasteczek jest również mylące. Sesje w PHP mogą współpracować z ciasteczkami do przechowywania identyfikatorów sesji, ale ich użycie nie jest tożsame z prostą obsługą ciasteczek, która dotyczy bardziej danych o preferencjach użytkowników. Obsługa formularzy również nie wymaga bezpośrednio sesji, chociaż można je używać do przechowywania danych z formularzy pomiędzy różnymi stronami. Typowym błędem jest mylenie koncepcji związanych z trwałością danych i ich dostępnością. Sesje są używane do przechowywania stanu użytkownika w ramach danej wizyty na stronie, a nie do wczytywania danych czy ustawień globalnych, stąd ich zastosowanie w tych kontekstach jest ograniczone i nieodpowiednie.
Pytanie 7
W wyniku przedstawionego polecenia w tabeli zostanie ```ALTER TABLE nazwa1 ADD nazwa2 DOUBLE NOT NULL;```
A. dodana kolumna nazwa2 z wymuszoną wartością DOUBLE
B. dodana kolumna nazwa2 o typie zmiennoprzecinkowym
C. zmieniona kolumna z nazwa1 na nazwa2
D. zmieniony typ kolumny nazwa2 na DOUBLE
Analizując pozostałe odpowiedzi, można zauważyć, że nie odzwierciedlają one poprawności działania zapytania SQL. Pierwsza odpowiedź sugeruje zmianę nazwy kolumny, co jest błędnym podejściem, ponieważ użycie klauzuli "ADD" wyraźnie wskazuje na dodanie nowej kolumny, a nie na modyfikację istniejącej. Zmiana nazwy kolumny wymagałaby użycia zapytania "ALTER TABLE ... RENAME COLUMN...", co jest zupełnie inną operacją. Drugie stwierdzenie koncentruje się na zmianie wartości kolumny "nazwa2" na typ DOUBLE, co jest niepoprawne, gdyż zapytanie nie zmienia wartości, a dodaje nową kolumnę. Ostatnia odpowiedź wskazuje na dodanie kolumny z wartością domyślną, co również jest błędne, gdyż w zapytaniu nie określono wartości domyślnej dla nowej kolumny. W rzeczywistości, przy dodawaniu kolumny można również ustawić wartość domyślną, ale nie jest to wymagane. Typowe błędy w myśleniu prowadzące do takich wniosków często wynikają z niepełnego zrozumienia składni SQL i funkcji poszczególnych poleceń. Dlatego istotne jest, aby przed przystąpieniem do modyfikacji struktury bazy danych dobrze zaznajomić się z dokumentacją i zasadami działania systemu zarządzania bazą danych, z którego się korzysta.
Pytanie 8
Jakim systemem do zarządzania wersjami oprogramowania jest
A. TotalCommander
B. FileZilla
C. Eclipse
D. GIT
TotalCommander, Eclipse i FileZilla to popularne narzędzia, które służą do innych celów w procesie tworzenia oprogramowania, ale nie są systemami kontroli wersji. TotalCommander jest menedżerem plików, który ułatwia nawigację i zarządzanie plikami na komputerze, jednak nie oferuje funkcji śledzenia zmian w kodzie czy współpracy zespołowej. Eclipse to zintegrowane środowisko programistyczne (IDE), które wspiera rozwój aplikacji, ale nie pełni roli systemu kontroli wersji, chociaż może korzystać z różnych systemów kontroli wersji za pomocą odpowiednich wtyczek. FileZilla to klient FTP, który umożliwia przesyłanie plików na serwery, co również nie ma związku z kontrolą wersji. Często mylnie przyjmuje się, że narzędzia związane z zarządzaniem plikami czy programowaniem mogą zastępować systemy kontroli wersji, co jest błędnym podejściem. Systemy kontroli wersji, takie jak GIT, są zaprojektowane z myślą o zarządzaniu zmianami w kodzie źródłowym, co jest kluczowe w nowoczesnym procesie wytwarzania oprogramowania. Ignorowanie tej specyfikacji i nieodróżnianie narzędzi do zarządzania plikami od systemów kontroli wersji może prowadzić do problemów w organizacji pracy zespołu oraz utraty wydajności w projektach.
Pytanie 9
Podaj zapytanie SQL, które tworzy użytkownika sekretarka na localhost z hasłem zaq123?
A. CREATE USER 'sekretarka'@'localhost' IDENTIFIED `zaq123`;
B. CREATE USER `sekretarka`@`localhost` IDENTIFIED BY 'zaq123';
C. CREATE USER `sekretarka`@`localhost` IDENTIFY "zaq123";
D. CREATE USER `sekretarka`@`localhost` IDENTIFY BY `zaq123`;
W analizowanych odpowiedziach można dostrzec kilka kluczowych błędów związanych z zarządzaniem użytkownikami w MySQL. Przykładowo, odpowiedź sugerująca użycie słowa kluczowego 'IDENTIFY' zamiast 'IDENTIFIED' jest niewłaściwa, ponieważ w kontekście MySQL nie istnieje tego typu polecenie. Takie nieprawidłowe zrozumienie składni SQL może prowadzić do nieudanych prób tworzenia użytkowników, co z kolei skutkuje frustracją i czasem straconym na debugowanie. Ponadto, odpowiedzi, które używają backticków (`) do oznaczania hasła, są niepoprawne. W SQL backticki służą do oznaczania identyfikatorów, takich jak nazwy tabel czy kolumn, a nie do łańcuchów tekstowych. Oznaczanie haseł przy użyciu backticków może prowadzić do nieprzewidywalnych błędów podczas wykonywania zapytań. Kolejnym problemem jest brak właściwego zrozumienia konwencji dotyczących użycia pojedynczych lub podwójnych cudzysłowów do definiowania łańcuchów. Użycie cudzysłowów zamiast apostrofów prowadzi do błędów składniowych. W kontekście bezpieczeństwa, każda nieprawidłowa próba utworzenia użytkownika może zagrażać integralności danych, dlatego ważne jest, aby korzystać z poprawnych praktyk, jak również ze zrozumienia zasad dotyczących zarządzania użytkownikami w systemie baz danych.
Pytanie 10
W znaczniku <meta ...> w sekcji <meta ...> na stronie internetowej nie zamieszcza się informacji o
A. kodowaniu
B. typie dokumentu
C. automatycznym odświeżaniu
D. autorze
Wszystkie wymienione odpowiedzi, z wyjątkiem informacji dotyczącej typu dokumentu, są poprawne i mogą być umieszczane w znaczniku <meta>. Informacja o autorze jest istotna, ponieważ pozwala wskazać osobę odpowiedzialną za treść na stronie, co może być ważne w kontekście cytowania i prawa autorskiego. Wyszukiwarki również mogą brać pod uwagę te informacje w kontekście wiarygodności źródła. Z kolei kodowanie jest kluczowe, ponieważ określa, w jaki sposób znaki są interpretowane przez przeglądarkę, co ma fundamentalne znaczenie dla prawidłowego wyświetlania treści, zwłaszcza w przypadku stron wielojęzycznych. Możliwość określenia kodowania w znaczniku <meta charset='UTF-8'> jest powszechnie stosowana, aby zapewnić, że wszystkie znaki są renderowane poprawnie. Automatyczne odświeżanie za pomocą znacznika <meta http-equiv='refresh' content='30'> jest przydatne, gdy strona potrzebuje być często aktualizowana, na przykład w przypadku stron informacyjnych czy serwisów newsowych. Dlatego też, umieszczanie tych informacji w znaczniku <meta> jest zgodne z praktykami webowymi i przyczynia się do poprawy działania strony oraz jej optymalizacji dla użytkowników i wyszukiwarek.
Pytanie 11
Semantyczny znacznik sekcji języka HTML 5 przeznaczony do umieszczenia stopki strony WWW to
W CSS należy ustawić tło dokumentu na obrazek rys.png. Obrazek powinien się powtarzać tylko w poziomej osi. Jaką definicję powinien mieć selektor body?
A. {background-image: url("rys.png"); background-repeat: repeat-x;}
B. {background-image: url("rys.png"); background-repeat: repeat-y;}
C. {background-image: url("rys.png"); background-repeat: round;}
D. {background-image: url("rys.png"); background-repeat: repeat;}
Wybrana odpowiedź {background-image: url("rys.png"); background-repeat: repeat-x;} jest poprawna, ponieważ precyzyjnie definiuje tło dokumentu jako obrazek 'rys.png', który ma się powtarzać wyłącznie w poziomie. W CSS, właściwość 'background-image' pozwala na ustawienie obrazu jako tła, a 'background-repeat' kontroluje, w jaki sposób tło się powtarza. Użycie wartości 'repeat-x' oznacza, że obrazek będzie powtarzany tylko w osi poziomej, co jest idealne dla wzorów, które powinny być rozciągnięte na całej szerokości ekranu, ale nie na wysokości. Przykładem zastosowania może być stworzenie tła z deseniem, które ma być widoczne w poziomie, np. paski lub linie, co jest powszechnie stosowane w projektowaniu stron internetowych. Zgodnie z dobrymi praktykami, warto również pamiętać, aby dostosować rozmiar obrazka do wymagań responsywności, aby zapewnić optymalne wyświetlanie na różnych urządzeniach.
Pytanie 13
W sekcji nagłówkowej kodu HTML znajduje się tekst przedstawiony na ilustracji. Tekst ten zostanie wyświetlony
<title>Strona miłośników psów</title>
A. w zawartości strony, w pierwszym widocznym nagłówku
B. w polu adresu, obok wpisanego adresu URL
C. w zawartości strony, na banerze
D. na pasku tytułowym przeglądarki
Element <title> w kodzie HTML jest często mylony z innymi znacznikami, które mogą wpływać na wyświetlanie treści strony. Znajduje się w sekcji <head> dokumentu i jest odpowiedzialny wyłącznie za wyświetlanie tytułu strony na pasku tytułu przeglądarki, co jest kluczowe dla zrozumienia jego roli. Błędne przekonanie, że tekst z tagu <title> pojawia się w treści strony, wynika z nieznajomości różnorodności znaczników HTML. Zamiast tego, nagłówki takie jak <h1>, <h2> i inne są używane do strukturyzowania treści strony i są widoczne dla użytkowników bezpośrednio na stronie. Mylenie tych funkcji prowadzi do niepoprawnego użycia znaczników, co skutkuje nieoptymalnym projektowaniem stron internetowych. Kolejnym częstym błędem jest założenie, że tytuł strony może być wyświetlany w polu adresu URL, co jest nieprawidłowe, ponieważ pole to pokazuje jedynie adres strony. Zrozumienie tych różnic jest kluczowe dla efektywnego kodowania i projektowania stron internetowych, a także dla poprawnej optymalizacji pod kątem wyszukiwarek internetowych, gdzie każde wyrażenie i jego pozycja w kodzie HTML ma znaczenie. Właściwe użycie tagu <title> to fundament dobrze zoptymalizowanej strony, co jest niezbędne w dzisiejszym środowisku cyfrowym.
Pytanie 14
Który z poniższych języków jest zazwyczaj używany do programowania front-endowego (wykonywanego po stronie klienta)?
A. CSS
B. PHP
C. Perl
D. Node.js
Node.js, Perl i PHP to języki programowania, które najczęściej służą do tworzenia logiki aplikacji po stronie serwera, a nie po stronie klienta. Node.js jest platformą opartą na JavaScript, która umożliwia uruchamianie kodu JavaScript na serwerze, co sprawia, że jest to środowisko do tworzenia aplikacji webowych, ale nie jest językiem front-endowym per se. Perl to język skryptowy, tradycyjnie używany do przetwarzania danych i automatyzacji, który również działa na serwerze, a nie w przeglądarkach. PHP, podobnie jak Perl, jest językiem skryptowym zaprojektowanym do generowania dynamicznych treści na stronach internetowych po stronie serwera. Typowy błąd myślowy polega na myleniu środowisk uruchomieniowych z rolą języka w architekturze aplikacji webowych. W rzeczywistości, języki front-endowe, takie jak CSS i JavaScript, są odzwierciedleniem interakcji użytkownika w przeglądarkach, podczas gdy Node.js, Perl i PHP pełnią inne funkcje, skupiając się na logice aplikacji, zarządzaniu danymi oraz komunikacji z bazami danych. Zrozumienie różnic między tymi podejściami jest kluczowe dla efektywnego projektowania aplikacji webowych i wykorzystania odpowiednich narzędzi w odpowiednich kontekstach.
Pytanie 15
Którą funkcję z menu Kolory programu GIMP użyto, w celu uzyskania efektu przedstawionego w filmie?
A. Progowanie.
B. Inwersja.
C. Barwienie.
D. Krzywe.
Prawidłowo wskazana funkcja to „Progowanie”, bo dokładnie ona zamienia obraz kolorowy lub w odcieniach szarości na obraz dwuwartościowy: piksel jest albo czarny, albo biały, w zależności od tego, czy jego jasność przekracza ustawiony próg. W GIMP-ie znajdziesz ją w menu Kolory → Progowanie. Suwakami ustalasz zakres poziomów jasności, które mają zostać potraktowane jako „białe”, a wszystko poza tym zakresem staje się „czarne”. Efekt, który się wtedy uzyskuje, jest bardzo charakterystyczny: mocno kontrastowy, bez półtonów, coś w stylu skanu czarno-białego lub grafiki do druku na ploterze tnącym. Z mojego doświadczenia progowanie świetnie nadaje się do przygotowania logotypów, szkiców technicznych, schematów, a także do wyciągania konturów z lekko rozmytych zdjęć. Często używa się go też przed wektoryzacją, żeby program śledzący krawędzie miał wyraźne granice między czernią a bielą. W pracy z grafiką na potrzeby stron WWW próg bywa stosowany np. przy tworzeniu prostych ikon, piktogramów albo masek (maski przezroczystości można przygotować właśnie na bazie obrazu progowanego). Dobrą praktyką jest najpierw sprowadzenie obrazu do odcieni szarości i dopiero potem użycie progowania, bo wtedy masz większą kontrolę nad tym, jak rozkłada się jasność i gdzie wypadnie granica progu. Warto też pamiętać, że progowanie jest operacją destrukcyjną – traci się informacje o półtonach – więc najlepiej pracować na kopii warstwy, żeby w razie czego móc wrócić do oryginału i poprawić ustawienia progu.
Pytanie 16
Co można powiedzieć o przedstawionym zapisie języka HTML5?
<title>Strona o psach</title>
A. Pojawi się na karcie dokumentu w przeglądarce.
B. Zostanie wyświetlony w treści strony, na samej górze.
C. Jest jedynie informacją dla robotów wyszukiwarek i nie jest wyświetlany przez przeglądarkę.
D. Jest opcjonalny w języku HTML5 i nie musi występować w dokumencie.
Brawo, Twoja odpowiedź jest prawidłowa! Znacznikiw języku HTML 5 służy do określenia tytułu strony internetowej, który jest wyświetlany na karcie przeglądarki. Nie jest to opcjonalna informacja - każda strona powinna mieć tytuł dla lepszej identyfikacji i optymalizacji SEO (Search Engine Optimization). Tytuł strony jest jednym z kluczowych elementów dla SEO, ponieważ wyszukiwarki internetowe, takie jak Google, często wykorzystują tytuł strony jako główny link w wynikach wyszukiwania. Tytuł strony jest również ważny z punktu widzenia użytkownika - dobrze sformułowany tytuł może przyciągnąć uwagę potencjalnego odbiorcy i zachęcić go do odwiedzenia strony. Warto zauważyć, że tytuł nie jest wyświetlany bezpośrednio na stronie, ale na pasku tytułu przeglądarki lub na karcie strony. To ważne rozróżnienie pomaga zrozumieć, dlaczego niektóre elementy są widoczne dla użytkownika, a inne nie.
Pytanie 17
W języku JavaScript przedstawiona poniżej definicja jest definicją var imiona=["Anna", "Jakub", "Iwona", "Krzysztof"];
A. kolekcji.
B. obiektu.
C. klasy.
D. tablicy.
W języku JavaScript definicja var imiona=["Anna", "Jakub", "Iwona", "Krzysztof"]; przedstawia tablicę, która jest jednym z fundamentalnych typów danych w tym języku. Tablice są używane do przechowywania zbiorów danych w sposób uporządkowany. W tym przypadku tablica imiona przechowuje cztery stringi, każdy reprezentujący imię. Wartością dodaną tablicy jest możliwość dostępu do poszczególnych elementów za pomocą indeksów, które zaczynają się od zera. Na przykład, imiona[0] zwróci \"Anna\", a imiona[1] zwróci \"Jakub\". W praktyce tablice są niezwykle przydatne w programowaniu, ponieważ pozwalają na łatwe zarządzanie i manipulację danymi. Dobrą praktyką jest używanie tablic do przechowywania związków danych, co umożliwia ich efektywne przetwarzanie i iterację za pomocą pętli, co zwiększa czytelność i organizację kodu. Warto również zaznaczyć, że tablice w JavaScript są obiektami, co daje dodatkowe możliwości manipulacji, takie jak metody tablicowe (np. push, pop, map, filter) do operacji na zbiorach danych. Poznanie i zrozumienie tablic jest kluczowe dla każdego programisty, ponieważ są one podstawą wielu algorytmów i struktur danych."
Pytanie 18
Aby z tabeli Pracownicy wybrać tylko nazwiska kończące się na literę „i”, można zastosować następującą kwerendę SQL
A. SELECT nazwisko FROM Pracownicy WHERE nazwisko LIKE "%i%";
B. SELECT nazwisko FROM Pracownicy WHERE nazwisko LIKE "i%";
C. SELECT nazwisko FROM Pracownicy WHERE nazwisko LIKE "i";
D. SELECT nazwisko FROM Pracownicy WHERE nazwisko LIKE "%i;
Prawidłowa kwerenda SQL do wyszukania nazwisk pracowników, których ostatnią literą jest 'i', to 'SELECT nazwisko FROM Pracownicy WHERE nazwisko LIKE "%i";'. Operator LIKE w SQL jest używany do wyszukiwania wzorców w danych tekstowych. W tym przypadku symbol '%' przed literą 'i' oznacza, że przed 'i' może występować dowolna liczba znaków (w tym zero), co umożliwia znalezienie wszystkich nazwisk kończących się na tę literę. Przykładowe nazwiska, które mogą być zwrócone przez tę kwerendę to 'Kowalski', 'Nowak', czy 'Wiśniewski'. Zgodnie z standardem SQL, użycie podwójnych cudzysłowów dla wzorca jest właściwe w kontekście baz danych, jednak w wielu systemach baz danych, w tym MySQL, częściej stosuje się pojedyncze cudzysłowy. Warto także zauważyć, że technika ta jest przydatna przy pracy z bazami danych, gdyż umożliwia elastyczne wyszukiwanie informacji oraz jest szczególnie cenne w aplikacjach wymagających filtrowania danych według specyficznych kryteriów.
Pytanie 19
W jaki sposób wykonanie podanej poniżej kwerendy SQL wpłynie na tabelę pracownicy?
ALTER TABLEpracownicyMODIFYplecchar9);
A. Doda kolumnę plec ze znakowym typem danych o stałej długości 9.
B. Zmieni typ danych kolumny plec na znakowy o zmiennej długości 9.
C. Zmieni typ danych kolumny plec na znakowy o stałej długości 9.
D. Doda kolumnę plec ze znakowym typem danych o zmiennej długości 9.
Zmiana kolumny 'plec' poprzez dodanie nowej kolumny zamiast modyfikacji istniejącej jest błędna, ponieważ kwerenda SQL ALTER TABLE z modyfikacją nie dodaje nowej kolumny, lecz zmienia atrybuty już istniejącej. W przypadku dodania kolumny z typem znakowym o stałej długości, nie byłoby to możliwe bez użycia innego polecenia, takiego jak ADD COLUMN, co jest całkowicie inną operacją. Ponadto, zmiana na typ danych o zmiennej długości nie ma zastosowania w tej sytuacji, ponieważ char(9) zawsze rezerwuje 9 znaków, niezależnie od tego, ile znaków faktycznie jest zapisanych, co jest kluczową różnicą w porównaniu do varchar, który jest typem zmiennej długości. Ostatnia niepoprawna odpowiedź sugeruje, że kolumna mogłaby mieć typ znakowy o zmiennej długości, co nie jest zgodne z definicją char, gdyż ten typ danych zawsze zarezerwuje maksymalną długość zdefiniowaną przez użytkownika. W praktyce oznacza to, że przy użyciu char(9) każda wartość w kolumnie 'plec' będzie zawsze składać się z 9 znaków, a w przypadku krótszych wartości zostaną one wypełnione spacjami. Zrozumienie różnicy między typami danych oraz ich właściwą modyfikację jest kluczowe dla efektywnego zarządzania bazami danych.
Pytanie 20
Jakie polecenie należy zastosować, aby cofnąć uprawnienia przyznane użytkownikowi?
A. REVOKE
B. GRANT NO PRIVILEGES
C. DROP PRIVILEGES
D. REMOVE
Polecenie REVOKE jest standardowym poleceniem w systemach zarządzania bazami danych, które służy do odebrania wcześniej przyznanych uprawnień użytkownikowi. Używając tego polecenia, administrator może skutecznie kontrolować dostęp do różnych zasobów w bazie danych. Na przykład, jeśli użytkownik A otrzymał uprawnienia do edytowania danych w tabeli 'Zamówienia', a administrator postanowi, że użytkownik A nie powinien mieć już takich uprawnień, może użyć polecenia REVOKE, aby je odebrać. W praktyce użycie REVOKE wygląda następująco: "REVOKE UPDATE ON Zamówienia FROM 'użytkownikA'". Dzięki temu podejściu administratorzy mogą zapewnić, że dostęp do wrażliwych danych jest odpowiednio zarządzany i zgodny z zasadami bezpieczeństwa danych. Dobrą praktyką jest regularne przeglądanie przyznanych uprawnień i ich aktualizacja w zależności od zmieniających się potrzeb organizacji oraz polityki zarządzania dostępem.
Pytanie 21
Jedną z charakterystyk relacyjnej bazy danych jest
A. używanie języka zapytań OQL
B. stosowanie kluczy głównych do identyfikacji rekordów w tabelach
C. obecność klas, obiektów i metod
D. zdefiniowanie jej stanu według obiektowego modelu danych
Relacyjne bazy danych opierają się na koncepcji tabel, gdzie dane są przechowywane w wierszach i kolumnach. Klucze główne odgrywają kluczową rolę w zapewnieniu unikalności rekordów w tabelach i umożliwiają ich identyfikację. Klucz główny to kolumna (lub zestaw kolumn), której wartości są unikalne w obrębie tabeli i nie mogą być puste. Przykładem może być tabela 'Użytkownicy', w której identyfikatorem użytkownika (kluczem głównym) może być numer PESEL lub unikalny ID. Dzięki kluczom głównym, można łatwo odnaleźć konkretne rekordy, a także powiązać je z innymi tabelami przy pomocy kluczy obcych, co jest fundamentalne dla relacyjnej struktury bazy danych. Standardy takie jak SQL (Structured Query Language) dostarczają narzędzi do definiowania, modyfikowania i manipulowania danymi z wykorzystaniem kluczy głównych, co jest podstawą projektowania baz danych zgodnie z najlepszymi praktykami. Dobre praktyki projektowe sugerują również, aby klucze główne były proste, stabilne i unikalne, co ułatwia zarządzanie danymi w relacyjnych systemach zarządzania bazą danych (RDBMS).
Pytanie 22
W dokumencie XHTML znajduje się fragment kodu, w którym występuje błąd walidacyjny. Co jest przyczyną tego błędu?
A. Znacznik <br> musi być zamknięty
B. Znacznik <b> nie może być umieszczany wewnątrz znacznika <p>
C. Nie ma nagłówka szóstego poziomu
D. Znaczniki powinny być pisane dużymi literami
Wybór odpowiedzi, że nie istnieje nagłówek szóstego stopnia, jest błędny, ponieważ w specyfikacji XHTML nagłówek szóstego stopnia <h6> jest jak najbardziej dopuszczalny i służy do oznaczania najmniej ważnych nagłówków, w hierarchii od <h1> do <h6>. Pisanie znaczników wielkimi literami nie jest wymogiem XHTML. Chociaż XHTML jest wrażliwy na wielkość liter, co oznacza, że nazwy znaczników i atrybutów muszą być pisane małymi literami, odpowiedź sugerująca, że tylko wielkie litery są poprawne, jest błędna. Użycie <b> jako zagnieżdżonego w <p> jest standardową praktyką i jest zgodne z normami XHTML, ponieważ <b> służy do pogrubienia tekstu wewnątrz elementu blokowego, jakim jest <p>. Problem z tą odpowiedzią polega na błędnym zrozumieniu struktury HTML, gdzie zagnieżdżanie elementów inline w elementach blokowych jest dozwolone. Ważnym aspektem jest umiejętność rozpoznania, które elementy są inline, a które blokowe, i jak mogą być poprawnie zagnieżdżane w kontekście specyfikacji XHTML. Poprawne zrozumienie tych zasad pomaga w tworzeniu wydajniejszych i bardziej zgodnych dokumentów internetowych.
Pytanie 23
Który znacznik lub grupa znaczników nie są stosowane do definiowania struktury strony HTML?
A. <section>
B. <header>, <footer>
C. <div>
D. <i>, <b>, <u>
Znacznik <i>, <b>, <u> jest stosowany głównie do celów prezentacyjnych, a nie do definiowania struktury dokumentu HTML. <i> oznacza tekst kursywą, <b> tekst pogrubiony, a <u> tekst podkreślony. Te znaczniki są częścią HTML, ale ich główną funkcją jest wzbogacenie wizualne treści, co nie ma związku z logiczną strukturą strony. W kontekście dobrych praktyk webowych, zaleca się stosowanie znaczników semantycznych, które dostarczają bardziej zrozumiałych informacji o treści strony wyszukiwarkom i asystentom technologicznym. Przykładowo, zamiast używać <b> dla podkreślenia znaczenia tekstu, warto skorzystać z <strong>, który również pogrubia tekst, ale dodatkowo wskazuje, że jest on istotny. Dobre praktyki sugerują, aby struktura strony była wyraźna i zrozumiała, co ułatwia nawigację oraz dostępność. Właściwe użycie znaczników takich jak <header>, <footer> czy <section> pomaga w tworzeniu jasnej i logicznej hierarchii dokumentu.
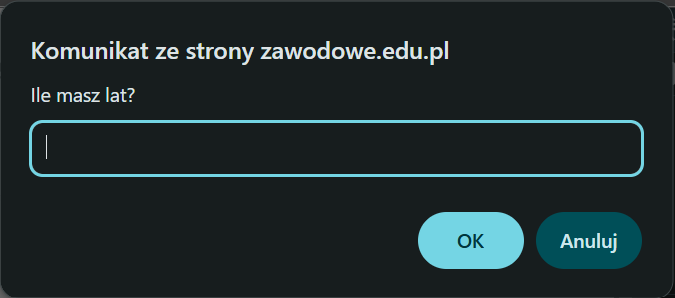
Pytanie 24
Którego polecenia JavaScript należy użyć, aby w oknie przeglądarki wyświetliło się okno przedstawione na obrazie?
A. prompt(’Ile masz lat?’)
B. document.write(’Ile masz lat?’)
C. confirm(’Ile masz lat?’)
D. alert(’Ile masz lat?’)
Prawidłowo – żeby wyświetlić w przeglądarce okno z polem tekstowym do wpisania odpowiedzi, trzeba użyć funkcji prompt(). W JavaScript wywołanie prompt('Ile masz lat?') powoduje pokazanie natywnego okna dialogowego z komunikatem oraz jednym polem input typu tekstowego. Funkcja zwraca to, co użytkownik wpisze, jako łańcuch znaków (string), albo null, jeśli kliknie „Anuluj”. Dzięki temu od razu możesz przypisać wynik do zmiennej, np.: const wiek = prompt('Ile masz lat?'); i dalej go przetwarzać w skrypcie, np. konwertować na liczbę: const wiekNum = Number(wiek); albo parseInt(wiek, 10). Z mojego doświadczenia prompt() jest często używany w prostych przykładach dydaktycznych, do szybkiego testowania logiki programu, np. pytanie o imię, wiek, hasło dostępu w wersji „demo”. W realnych aplikacjach produkcyjnych raczej unika się prompt(), bo jest mało elastyczny, trudno go ostylować i blokuje interfejs (jest modalny i synchroniczny). Standardem branżowym jest budowanie własnych okien dialogowych w HTML/CSS/JS, np. z użyciem <dialog>, frameworków UI albo bibliotek typu modal. Jednak do nauki podstaw JavaScript, zrozumienia przepływu danych między użytkownikiem a skryptem i pokazania prostych interakcji prompt() jest bardzo wygodny. Warto też pamiętać, że prompt zawsze zwraca tekst, więc jeśli dalej chcesz wykonywać obliczenia, to zgodnie z dobrymi praktykami najpierw jawnie rzutuj go na typ liczbowy i sprawdź, czy użytkownik nie wpisał bzdury (isNaN, walidacja zakresu itp.).
Pytanie 25
Parkowanie domeny to proces, który polega na
A. nabyciu nowej domeny
B. stworzeniu strefy domeny i wskazaniu serwerów DNS
C. zmianie właściciela domeny poprzez cesję
D. dodaniu aliasu CNAME dla domeny
Zakup nowej domeny nie jest tożsamy z parkowaniem domeny, ponieważ odnosi się do etapu, w którym użytkownik nabywa prawo do jej używania. Chociaż zakupienie domeny jest pierwszym krokiem do jej późniejszego używania, nie wiąże się bezpośrednio z jej parkowaniem. Wprowadzenie aliasu CNAME dla domeny również nie jest związane z parkowaniem. Alias CNAME jest używany do przekierowywania zapytań DNS z jednej domeny na inną i może być stosowany dopiero po skonfigurowaniu strefy. Zmiana abonenta domeny przez cesję dotyczy transferu praw do domeny, co również nie ma związku z jej parkowaniem. Właściwe parkowanie domeny polega na jej skonfigurowaniu w sposób umożliwiający jej zarządzanie, co nie jest realizowane przez same zakupy, aliasy czy cesje. Często mylenie tych koncepcji prowadzi do dezorientacji w zakresie zarządzania domenami. Aby prawidłowo parkować domenę, konieczne jest zrozumienie roli serwerów DNS oraz strefy domeny, co jest kluczowe dla przyszłego wykorzystania domeny w Internecie.
Pytanie 26
W języku PHP symbol "//" oznacza
A. operator alernatywy
B. początek skryptu
C. początek komentarza jednoliniowego
D. operator dzielenia całkowitego
W PHP znak "//" oznacza początek komentarza jednoliniowego. Komentarze są niezwykle ważnym elementem kodu, ponieważ pozwalają programistom na dodawanie objaśnień i notatek, które nie są wykonywane przez interpreter. Dzięki temu kod staje się bardziej czytelny i łatwiejszy w utrzymaniu, zwłaszcza w projektach zespołowych czy przy dłuższych skryptach. Na przykład, można użyć komentarza, aby wyjaśnić, jak działa dana funkcjonalność lub dlaczego podjęto określoną decyzję projektową. Ponadto, stosowanie komentarzy zgodnie z dobrymi praktykami zwiększa jakość dokumentacji projektu oraz ułatwia przyszłym programistom (lub samemu autorowi) zrozumienie logiki kodu. Warto również zauważyć, że w PHP istnieją inne sposoby komentowania, takie jak "#" dla komentarzy jednoliniowych oraz "/* ... */" dla komentarzy wieloliniowych. Użycie komentarzy w kodzie źródłowym jest istotnym aspektem programowania, promującym najlepsze praktyki związane z czytelnością i zarządzaniem projektami.
Pytanie 27
W bazie danych księgarni znajduje się tabela ksiazki, która zawiera pola: id, idAutor, tytul, ileSprzedanych, oraz tabela autorzy z polami: id, imie, nazwisko. Jak można utworzyć raport sprzedanych książek zawierający tytuły oraz nazwiska autorów?
A. należy zdefiniować relację 1..1 pomiędzy tabelami ksiazki a autorzy, a następnie stworzyć kwerendę łączącą obie tabele
B. należy zdefiniować relację l..n pomiędzy tabelami ksiazki a autorzy, a następnie stworzyć kwerendę łączącą obie tabele
C. trzeba utworzyć dwie oddzielne kwerendy: pierwsza do wyszukiwania tytułów książek, druga do wyszukiwania nazwisk autorów
D. konieczne jest stworzenie kwerendy, która wyszukuje tytuły książek
Relacja l..n między tabelami 'ksiazki' i 'autorzy' jest naprawdę ważna. To oznacza, że jeden autor może napisać kilka książek, co jest całkiem normalne w świecie księgarni. Dzięki tej relacji, dla każdego 'idAutor' w tabeli 'ksiazki' możemy mieć wiele wpisów, co super ułatwia powiązanie tytułów z autorami. Jakbyś stworzył kwerendę, która łączy te obie tabele, to bez problemu uzyskasz dane, które jasno pokazują te relacje. Na przykład, taka kwerenda SQL mogłaby wyglądać tak: SELECT ksiazki.tytul, autorzy.nazwisko FROM ksiazki JOIN autorzy ON ksiazki.idAutor = autorzy.id; Taki sposób działania jest zgodny z normalizacją danych, co sprawia, że nasze bazy danych będą efektywne i dobrze zorganizowane.
Pytanie 28
Aby skorzystać z relacji w zapytaniu, trzeba użyć słowa kluczowego
A. GROUP BY
B. UNION
C. IN
D. JOIN
Słowo kluczowe JOIN jest niezbędne do łączenia danych z różnych tabel w bazach danych relacyjnych. Umożliwia ono wykonanie zapytań, które wykorzystują powiązania między tabelami na podstawie wspólnych kolumn. Istnieje kilka rodzajów JOIN, w tym INNER JOIN, LEFT JOIN, RIGHT JOIN oraz FULL JOIN, z których każdy ma swoje specyficzne zastosowanie. Na przykład, używając INNER JOIN, można uzyskać tylko te rekordy, które mają odpowiadające wartości w obu tabelach. To podejście jest zgodne z zasadami normalizacji baz danych, które zalecają przechowywanie danych w sposób zminimalizowany, a relacje między danymi powinny być zarządzane przy użyciu kluczy obcych. Praktyczne zastosowanie JOIN jest kluczowe w analizie danych, gdzie często niezbędne jest zestawienie informacji z różnych źródeł, co pozwala na uzyskanie pełniejszego obrazu analizowanego problemu. Wiedza o tym, jak prawidłowo stosować JOIN, jest fundamentem pracy z bazami danych, a jej znajomość jest również wymagana w standardach branżowych związanych z zarządzaniem danymi.
Pytanie 29
Jakie uprawnienia są wymagane do tworzenia i przywracania kopii zapasowej bazy danych Microsoft SQL Server 2005 Express?
A. Użytkownik lokalny.
B. Użytkownicy zabezpieczeń.
C. Użytkownicy.
D. Administrator systemu.
Odpowiedzi wskazujące na 'Users', 'Security users' oraz 'Użytkownik lokalny' nie są poprawne w kontekście wymagań dotyczących wykonywania i odtwarzania kopii zapasowych w Microsoft SQL Server 2005 Express. Użytkownicy z rolą 'Users' mają ograniczone uprawnienia, które nie pozwalają im na wykonywanie operacji administracyjnych, takich jak tworzenie kopii zapasowych. Ich uprawnienia koncentrują się głównie na korzystaniu z danych i wykonywaniu zapytań, co nie obejmuje operacji związanych z bezpieczeństwem i zarządzaniem danymi. Podobnie, rola 'Security users' obejmuje uprawnienia związane z bezpieczeństwem, jednak nie daje możliwości zarządzania bazami danych w pełnym zakresie. Tego typu użytkownicy mogą mieć dostęp do niektórych funkcji związanych z bezpieczeństwem, ale nie są w stanie wykonywać krytycznych operacji takich jak tworzenie kopii zapasowych. Użytkownik lokalny, z kolei, odnosi się do systemowych użytkowników, którzy mają dostęp do komputera lokalnego, ale ich uprawnienia w kontekście Microsoft SQL Server 2005 Express są ograniczone i nie obejmują funkcji administracyjnych niezbędnych do zarządzania bazami danych. W praktyce, aby zapewnić odpowiednie bezpieczeństwo i integralność danych, konieczne jest, aby do operacji związanych z kopiami zapasowymi byli upoważnieni jedynie użytkownicy z pełnymi uprawnieniami administracyjnymi, co w tym przypadku odnosi się do roli administratora systemu.
Pytanie 30
Można wydać instrukcję transakcyjną ROLLBACK, aby
A. cofnąć transakcję po zastosowaniu instrukcji COMMIT
B. zatwierdzić jedynie wybrane modyfikacje transakcji
C. zatwierdzić transakcję
D. cofnąć działanie transakcji
Każda odpowiedź, która nie odnosi się do właściwego działania instrukcji ROLLBACK, wykazuje istotne nieporozumienia dotyczące transakcji w bazach danych. Na przykład, stwierdzenie, że ROLLBACK jest używane do zatwierdzania transakcji, jest fundamentalnie błędne. Zatwierdzanie transakcji, zazwyczaj realizowane za pomocą instrukcji COMMIT, polega na zapisaniu wszystkich zmian dokonanych w ramach transakcji w bazie danych. W przeciwieństwie do tego, ROLLBACK jest środkiem ochrony, pozwalającym na cofnięcie wszelkich zmian, które mogły zostać wykonane przed jego wywołaniem. Do tego dochodzi błędne uznanie, że ROLLBACK może cofnąć tylko wybrane modyfikacje transakcji, co jest niezgodne z jego zasadniczą funkcją. ROLLBACK działa na całej transakcji, a nie na jej poszczególnych elementach, co jest kluczowe dla zapewnienia spójności stanu bazy danych. Warto również zauważyć, że instrukcja ROLLBACK nie może być używana po zastosowaniu instrukcji COMMIT, ponieważ COMMIT ostatecznie kończy transakcję i zapisuje wszystkie zmiany, co czyni je nieodwracalnymi. Te błędne koncepcje mogą prowadzić do poważnych problemów w aplikacjach bazodanowych, takich jak utrata danych, niespójności czy awarie systemów, dlatego kluczowe jest zrozumienie właściwego działania mechanizmów transakcyjnych i ich zastosowania w praktyce.
Pytanie 31
Jakie ustawienia dotyczące czcionki będą miały zastosowanie w przypadku kodu CSS?
*{font-family:Tahoma;color:Teal;}
A. wszystkiego kodu HTML, niezależnie od kolejnych ustawień CSS.
B. wszystkiego kodu HTML, jako domyślne formatowanie dla wszystkich elementów strony.
C. znaczników o identyfikatorze równym *.
D. znaczników z klasą przypisaną jako *.
Wybór opcji dotyczącej całego kodu HTML jako formatowania domyślnego dla wszystkich elementów strony jest poprawny, ponieważ użycie selektora uniwersalnego * w CSS oznacza, że wszystkie dostępne elementy na stronie będą dziedziczyć określone style. W tym przypadku, zarówno font-family ustawiony na Tahoma, jak i kolor tekstu zmieniony na Teal, będą dotyczyły każdego elementu HTML, bez względu na jego typ. To podejście jest zgodne z zasadami stosowania stylów kaskadowych, gdzie style są aplikowane do elementów w sposób hierarchiczny, a selektor uniwersalny jest najogólniejszym z dostępnych. Przykładem zastosowania może być sytuacja, gdy chcemy ustawić jednolite formatowanie dla całej strony, co upraszcza proces projektowania i zapewnia spójność wizualną. Dobrą praktyką jest jednak używanie selektora uniwersalnego z umiarem, aby uniknąć nadmiernego obciążenia wydajności, szczególnie w większych dokumentach, gdzie precyzyjniejsze selektory mogą przynieść lepsze rezultaty.
Pytanie 32
Z którego z pól klasy
class Dane{public$a;private$b;protected$c;}
będzie można uzyskać dostęp z zewnątrz przy użyciu obiektu stworzonego jako instancja tej klasy?
A. Do pola $b.
B. Do pola $c.
C. Do wszystkich pól.
D. Do pola $a.
Odpowiedzi wskazujące na dostęp do wszystkich pól, pola $b oraz pola $c są wynikiem nieporozumienia dotyczącego zasad działania modyfikatorów dostępu w programowaniu obiektowym. Modyfikator public oznacza, że pole jest dostępne z każdego miejsca w kodzie, co jest prawdziwe tylko w przypadku pola $a. Natomiast pole $b, będące prywatnym, jest dostępne wyłącznie wewnątrz klasy Dane, co uniemożliwia dostęp z zewnątrz, co często prowadzi do błędnych wniosków, że wszystkie pola powinny być dostępne. W przypadku pola $c, które jest chronione, dostęp do niego mają tylko samodzielne instancje klasy oraz klasy pochodne, co również nie pozwala na dostęp z zewnątrz. W praktyce, wiele osób, które uczą się programowania obiektowego, może mylić te dwa poziomy dostępu i w konsekwencji przyjmować, że pola chronione mogą być używane w podobny sposób jak publiczne. Z tego powodu ważne jest zrozumienie podstawowych zasad modyfikatorów dostępu oraz ich wpływu na bezpieczeństwo i organizację kodu, co jest kluczowe w dobrych praktykach programowania.
Pytanie 33
W języku PHP, dla zmiennych a = 5 oraz b = 3, jakie wyrażenie zwróci wartość zmiennoprzecinkową?
A. a * b
B. a / b
C. a + b
D. a && b
W języku PHP operacje na zmiennych numerycznych mogą prowadzić do różnych typów wyników w zależności od zastosowanego operatora. W przypadku zmiennych a = 5 i b = 3, jeśli wykonamy operację a / b, uzyskamy wynik 1.6666666666667, co jest wartością zmiennoprzecinkową. Operacja dzielenia w PHP zawsze zwraca wynik typu float, gdy jest wykonywana na liczbach całkowitych, o ile nie jest to dzielenie całkowite przez zero. Wartość ta można wykorzystać w różnych kontekstach, np. w obliczeniach finansowych, gdzie precyzyjne wartości dziesiętne są kluczowe. Warto również zauważyć, że PHP automatycznie konwertuje typy, co oznacza, że operacje na mieszanych typach (np. integer i float) również będą skutkować wynikiem o typie float. Przykładem może być sytuacja, w której wynik dzielenia jest dalej używany w operacjach matematycznych, co może znacząco wpłynąć na końcowy rezultat. Z punktu widzenia standardów PHP, operacje arytmetyczne są ściśle określone w dokumentacji i warto zaznajomić się z funkcjami związanymi z operacjami na liczbach, aby w pełni wykorzystać możliwości języka.
Pytanie 34
W HTML, aby dodać obrazek z tekstem umieszczonym pośrodku obrazka, konieczne jest użycie znacznika
A. <img src="obrazek.png" alt="obraz2" align="middle"> tekst
B. <img src="obrazek.png" alt="obraz3" height="50%"> tekst
C. <img src="obrazek.png" alt="obraz4"> tekst
D. <img src="obrazek.png" alt="obraz1" hspace="30px"> tekst
Odpowiedzi, które nie są poprawne, zawierają różne koncepcje i podejścia, które nie spełniają wymogów wyśrodkowania tekstu wokół obrazka. Na przykład, użycie <img src="obrazek.png" alt="obraz3" height="50%"> tekst jest niewłaściwe, ponieważ atrybut height nie wpływa na położenie tekstu w stosunku do obrazka. W rzeczywistości, atrybut ten jedynie zmienia wysokość obrazka, co nie ma związku z umiejscowieniem tekstu. To podejście może prowadzić do błędnych wniosków, że zmiana wymiarów obrazka automatycznie wpływa na układ tekstu, co jest mylne. Z kolei, <img src="obrazek.png" alt="obraz4"> tekst nie zawiera żadnych atrybutów, które mogłyby zdefiniować położenie tekstu, co sprawia, że tekst będzie po prostu wyświetlany obok obrazka, bez jakiejkolwiek kontroli nad jego wyrównaniem. W kontekście nowoczesnych standardów HTML5, brak zastosowania CSS do stylizacji układu nie tylko obniża estetykę strony, ale również nie spełnia oczekiwań dotyczących dostępności. Wiele aplikacji internetowych i stron korzysta z CSS do precyzyjnego zarządzania położeniem elementów, co jest zgodne z zasadami responsywnego projektowania. Użycie atrybutu align z wartością middle w odpowiedzi 2 jest najodpowiedniejszym sposobem na zapewnienie poprawnego wyśrodkowania tekstu, co jest kluczowe w projektowaniu stron internetowych, gdzie zarówno estetyka, jak i funkcjonalność mają duże znaczenie.
Pytanie 35
W kodzie źródłowym zapisanym w języku HTML wskaż błąd walidacji dotyczący tego fragmentu: ```
CSS
Kaskadowe arkusze stylów (ang. Cascading Style Sheets) to język służący ...```
A. Znacznik zamykający /b niezgodny z zasadą zagnieżdżania.
B. Nieznany znacznik h6.
C. Znacznik br nie został poprawnie zamknięty.
D. Znacznik br nie może występować wewnątrz znacznika p.
Twoja odpowiedź jest poprawna. Znacznik zamykający /b w badanym kodzie HTML jest niezgodny z zasadą zagnieżdżania. Zasada ta mówi, że znaczniki powinny być zamykane w odwrotnej kolejności do otwierania - zgodnie z modelem LIFO (Last In, First Out). W praktyce oznacza to, że jeśli otworzyliśmy na przykład najpierw znacznik <i>, a następnie <b>, to najpierw powinniśmy zamknąć <b>, a dopiero potem <i>. Nieprzestrzeganie tej zasady może prowadzić do nieoczekiwanych wyników podczas renderowania strony. Jest to istotne dla utrzymania czytelności i prawidłowego funkcjonowania kodu. W codziennej praktyce, szczególnie w większych projektach, stosowanie się do takich zasad pomaga utrzymać kod zrozumiałym i łatwym do zarządzania.
Pytanie 36
W języku SQL, aby z tabeli Uczniowie wyodrębnić rekordy dotyczące wyłącznie uczennic o imieniu "Aleksandra", które przyszły na świat po roku "1998", należy sformułować zapytanie
A. SELECT * FROM Uczniowie WHERE imie="Aleksandra" AND rok_urodzenia > "1998"
B. SELECT * FROM Uczniowie WHERE imie ="Aleksandra" OR rok_urodzenia < "1998"
C. SELECT * FROM Uczniowie WHERE imie="Aleksandra" OR rok_urodzenia > "1998"
D. SELECT * FROM Uczniowie WHERE imie="Aleksandra" AND rok_urodzenia < "1998"
Ta odpowiedź jest prawidłowa, ponieważ wykorzystuje operator logiczny AND, aby jednocześnie spełnić dwa kryteria: imię uczennicy musi być równe 'Aleksandra', a rok urodzenia musi być większy niż 1998. Użycie AND zapewnia, że tylko te rekordy, które spełniają obydwa warunki, zostaną zwrócone, co jest zgodne z wymaganiami zadania. W praktyce, takie zapytanie mogłoby być użyte w systemie edukacyjnym do generowania raportów dla nauczycieli, aby zidentyfikować i analizować uczennice o konkretnych cechach. Stosowanie operatora AND jest zgodne z dobrymi praktykami w SQL, które preferują precyzyjne określenie warunków w zapytaniach. Warto również zauważyć, że w bazach danych, zapewnienie poprawności danych i odpowiednich filtrów na poziomie zapytań jest kluczowe, aby uniknąć błędnych analiz oraz zapewnić, że wyciągane informacje są rzetelne i użyteczne w kontekście podejmowania decyzji.
Pytanie 37
Do podzbioru DML (ang. Data Manipulation Language) języka SQL należą polecenia:
A. CREATE, DROP, ALTER
B. BEGIN, COMMIT, ROLLBACK
C. INSERT, UPDATE, DELETE
D. GRANT, REVOKE, DENY
W SQL bardzo łatwo pomylić różne grupy poleceń, bo wszystkie wyglądają podobnie, a jednak należą do innych podzbiorów języka. Podzbiór DML (Data Manipulation Language) dotyczy wyłącznie operacji na danych w tabelach: wstawiania, modyfikowania, usuwania i odczytu rekordów. Dlatego do DML zaliczamy przede wszystkim INSERT, UPDATE, DELETE oraz w wielu opracowaniach także SELECT. Wszystko to, co zmienia zawartość tabel, a nie ich definicję czy uprawnienia. Częsty błąd polega na wrzucaniu do jednego worka wszystkich poleceń SQL, bo „to też jest praca na bazie danych”. Na przykład CREATE, DROP i ALTER należą do DDL (Data Definition Language). One definiują strukturę bazy: tworzą tabele, usuwają je, zmieniają kolumny. To są operacje na schemacie bazy, a nie na rekordach. W praktyce używasz ich przy projektowaniu lub migracjach, a nie przy codziennej pracy aplikacji na danych użytkowników. Z kolei GRANT, REVOKE i DENY to klasyka DCL (Data Control Language). Te polecenia sterują uprawnieniami: kto może wykonywać SELECT, INSERT czy DELETE na danej tabeli, kto może tworzyć obiekty, itd. To już bardziej klimat administracji i bezpieczeństwa niż typowej manipulacji rekordami. BEGIN, COMMIT i ROLLBACK też bywają mylące. Dotyczą transakcji i zalicza się je zwykle do TCL (Transaction Control Language). One nie dodają ani nie zmieniają pojedynczego rekordu, tylko kontrolują „pakiet” operacji DML: pozwalają zatwierdzić lub wycofać całą serię INSERT/UPDATE/DELETE. Typowy błąd myślowy jest taki: skoro coś ma związek z danymi lub ich bezpieczeństwem, to pewnie DML. A jednak standardy i dobra praktyka wyraźnie rozdzielają DDL, DML, DCL i TCL, bo to pomaga lepiej rozumieć odpowiedzialność poszczególnych instrukcji i projektować bezpieczniejsze aplikacje. W codziennej pracy programisty webowego DML to głównie to, co stoi „pod spodem” formularzy: zapisywanie, edycja i kasowanie rekordów, a nie zarządzanie strukturą czy uprawnieniami.
Pytanie 38
Poniżej zamieszczony fragment skryptu w JavaScript zwróci
A. ze
B. owodzeni
C. wodzenia
D. wo
Ten skrypt w JavaScript zaczyna od zadeklarowania zmiennej x, której przypisywana jest fraza 'Powodzenia na egzaminie'. Potem korzysta z metody substring na tej zmiennej z parametrami (3, 9). To znaczy, że wyciąga kawałek tekstu od indeksu 3 do 9. Pamiętaj, w JavaScript liczymy od zera, więc indeks 3 to czwarty znak, czyli 'o'. Dlatego z.substring(3, 9) zwraca 'odzeni'. Następnie, robimy kolejne wywołanie substring na tym wyniku, z parametrami (2, 4), co daje nam fragment od indeksu 2 do 4 w 'odzeni', czyli 'ze'. Na końcu, funkcja document.write(y) pokaże ten wynik na stronie. To świetny przykład na to, jak manipulować tekstem, co jest naprawdę przydatne w pracy z danymi. Z mojej perspektywy, zrozumienie operacji na tekstach to klucz do skutecznego przetwarzania i prezentacji informacji. Użycie takich metod w JavaScript do pracy z tekstem to absolutna podstawa, z którą warto się zapoznać.
Pytanie 39
Aby dostosować dźwięk do określonego poziomu głośności, trzeba zastosować efekt
A. normalizacji
B. usuwania szumów
C. wyciszenia
D. podbicia basów
Wyciszenie, podbicie basów oraz usuwanie szumów to różne techniki przetwarzania dźwięku, które mają odmienne cele i funkcje. Wyciszenie jest procesem, w którym poziom głośności dźwięku jest redukowany, co nie prowadzi do normalizacji, a wręcz przeciwnie, zmniejsza ogólną głośność materiału audio. Użytkownicy mogą mylić wyciszenie z normalizacją, myśląc, że obie techniki mają na celu zwiększenie głośności, podczas gdy w rzeczywistości wyciszenie jest stosowane w celu eliminacji dźwięków niepożądanych lub cichszych fragmentów nagrania. Podbicie basów to proces, który koncentruje się na wzmocnieniu niskich częstotliwości w dźwięku, co może prowadzić do nieproporcjonalnej głośności, ale nie dostosowuje ogólnego poziomu głośności materiału. To podejście często skutkuje zniekształceniem dźwięku, co jest sprzeczne z zasadą normalizacji. Z kolei usuwanie szumów polega na eliminacji niechcianych dźwięków tła, co z kolei wpływa na jakość nagrania, ale nie ma bezpośredniego związku z poziomem głośności dźwięku. Użytkownicy mogą błędnie sądzić, że redukcja szumów zwiększa głośność, co jest mylnym przekonaniem. Właściwa normalizacja dźwięku jest kluczowym krokiem w produkcji audio, który zapewnia spójność i jakość dźwięku, a techniki takie jak wyciszenie, podbicie basów i usuwanie szumów pełnią inne role w tym procesie.
Pytanie 40
Podczas weryfikacji pliku HTML5 pojawił się komunikat brzmiący: "Error: Element head is missing a required instance of child element title". Co to oznacza w kontekście dokumentu?
A. element <title> nie został prawidłowo zamknięty przez </title>.
B. nie zdefiniowano obowiązkowego atrybutu title w tagu <img>.
C. nie zdefiniowano elementu <title> w sekcji <head> dokumentu.
D. element <title> nie jest konieczny.
Twoja odpowiedź jest całkowicie trafna! Zgodnie z tym, co mówi specyfikacja HTML5, element <title> rzeczywiście jest obowiązkowy i musi znaleźć się w sekcji <head>. To bardzo ważne, bo tytuł strony to coś, co pokazuje się na karcie przeglądarki, a także w wynikach wyszukiwania. Jak go brakuje, to strona nie spełnia podstawowych wymogów i pojawia się błąd walidacji. Fajnie jest mieć unikalne i opisowe tytuły dla każdej strony, bo to korzystnie wpływa na SEO i użyteczność. Na przykład, jeśli robiłbyś stronę o kulinariach, to tytuł mógłby być "Przepisy na zdrowe obiady", co od razu informuje użytkowników i wyszukiwarki, o co chodzi. Dobrze dobrany tytuł to naprawdę kluczowa sprawa, bo ma duży wpływ na to, jak użytkownicy postrzegają Twoją stronę i czy klikną w link. Pamiętaj też, że element <title> powinien być krótki, ale wystarczająco informacyjny, zazwyczaj nie dłuższy niż 60 znaków.
Odtwarzaj przebieg egzaminu krok po kroku i ucz się na własnych błędach. Widzisz dokładnie, w jakiej kolejności rozwiązywałeś pytania, ile czasu spędziłeś nad każdym z nich i kiedy zmieniałeś odpowiedzi.
Co znajdziesz na stronie przebiegu:
Suwak czasu
Przesuwaj i przeglądaj pytania w kolejności, w jakiej je rozwiązywałeś
Tryb nauki
Włącz, aby zobaczyć poprawne odpowiedzi i wyjaśnienia do pytań
Analiza czasu
Sprawdź, ile czasu spędziłeś nad każdym pytaniem i gdzie traciłeś czas
Monitoring focusu
Widzisz momenty, gdy opuściłeś zakładkę - tak jak widzi to nauczyciel
Strona wykorzystuje pliki cookies do poprawy doświadczenia użytkownika oraz analizy ruchu. Szczegóły
Polityka plików cookies
Czym są pliki cookies?
Cookies to małe pliki tekstowe, które są zapisywane na urządzeniu użytkownika podczas przeglądania stron internetowych. Służą one do zapamiętywania preferencji, śledzenia zachowań użytkowników oraz poprawy funkcjonalności serwisu.
Jakie cookies wykorzystujemy?
Niezbędne cookies - konieczne do prawidłowego działania strony
Funkcjonalne cookies - umożliwiające zapamiętanie wybranych ustawień (np. wybrany motyw)
Analityczne cookies - pozwalające zbierać informacje o sposobie korzystania ze strony
Jak długo przechowujemy cookies?
Pliki cookies wykorzystywane w naszym serwisie mogą być sesyjne (usuwane po zamknięciu przeglądarki) lub stałe (pozostają na urządzeniu przez określony czas).
Jak zarządzać cookies?
Możesz zarządzać ustawieniami plików cookies w swojej przeglądarce internetowej. Większość przeglądarek domyślnie dopuszcza przechowywanie plików cookies, ale możliwe jest również całkowite zablokowanie tych plików lub usunięcie wybranych z nich.