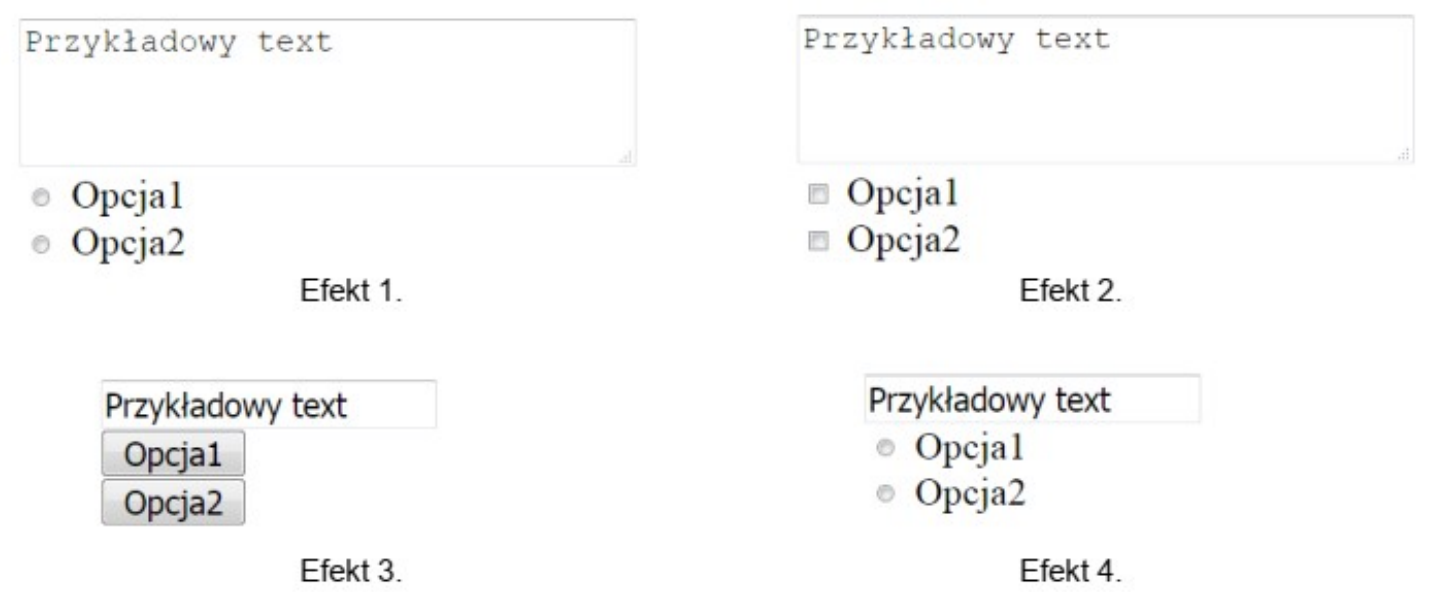
Pytanie 1
Do jakich działań można wykorzystać program FileZilla?
A. walidacji strony internetowej.
B. debugowania skryptu na stronie.
C. publikacji strony internetowej.
D. kompilacji skryptu na stronie.
FileZilla jest popularnym klientem FTP (File Transfer Protocol), który służy do przesyłania plików między lokalnym komputerem a serwerem. Publikacja strony internetowej polega na przesyłaniu plików HTML, CSS, JavaScript i innych zasobów związanych z witryną na serwer, aby były one dostępne w Internecie. Używając FileZilla, użytkownik może łatwo połączyć się z serwerem poprzez protokół FTP, co pozwala na wygodne zarządzanie plikami, ich przesyłanie oraz organizowanie folderów na serwerze. Przykładowo, po edytowaniu strony lokalnie na komputerze, można za pomocą FileZilla przesłać zmodyfikowane pliki na serwer w kilka kliknięć, co przyspiesza proces aktualizacji witryny. Zgodnie z dobrymi praktykami branżowymi, ważne jest także ustawienie odpowiednich uprawnień do plików oraz regularne tworzenie kopii zapasowych, co zwiększa bezpieczeństwo publikowanych treści. FileZilla obsługuje również protokoły SFTP i FTPS, które zapewniają dodatkowe warstwy bezpieczeństwa podczas transferu danych, co jest istotne w kontekście ochrony danych użytkowników i integracji z różnymi usługami hostingowymi.