Pytanie 1
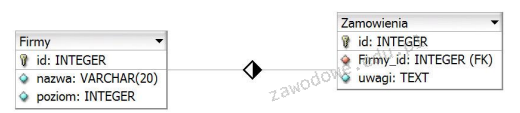
Model, w którym wszystkie dane są zapisane w jednej tabeli, określa się mianem
A. hierarchicznym
B. jednorodnym
C. relacyjnym
D. sieciowym
Model jednorodny to taka podstawowa struktura w bazach danych, gdzie wszystko trzymamy w jednej tabeli. To się fajnie sprawdza w prostych aplikacjach, bo wtedy relacje między danymi są dość oczywiste. Klasycznym przykładem może być baza kontaktów, gdzie każdy ma swoje info w jednym miejscu. Dzięki temu mamy łatwy dostęp do danych i prosto nimi zarządzać. Z mojego doświadczenia, to rozwiązanie jest super efektywne, ale jak system staje się większy i złożony, to zaczynają się schody. Wtedy inne modele, jak relacyjne, mogą mieć więcej sensu. W branży często korzysta się z modelu jednorodnego, zwłaszcza tam, gdzie szybki dostęp do danych jest kluczowy, a sztywne struktury tylko przeszkadzają. Na codzień to naprawdę przydatna rzecz, jak ktoś nie chce się męczyć z komplikacjami.