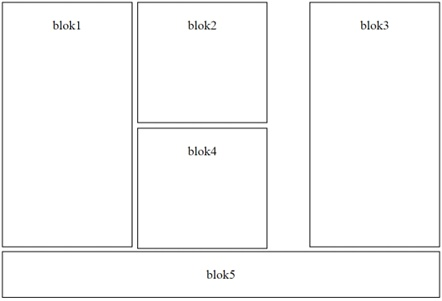
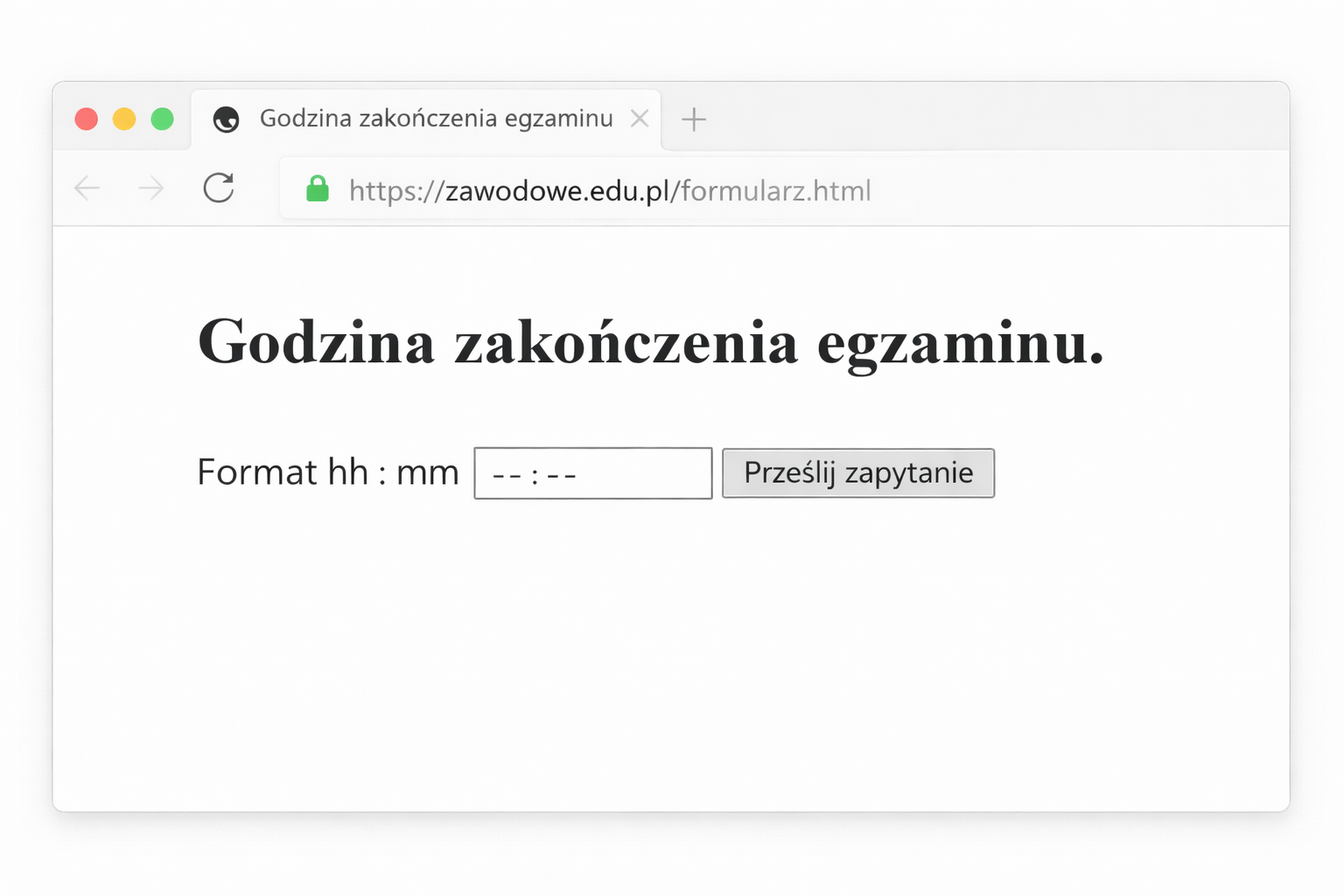
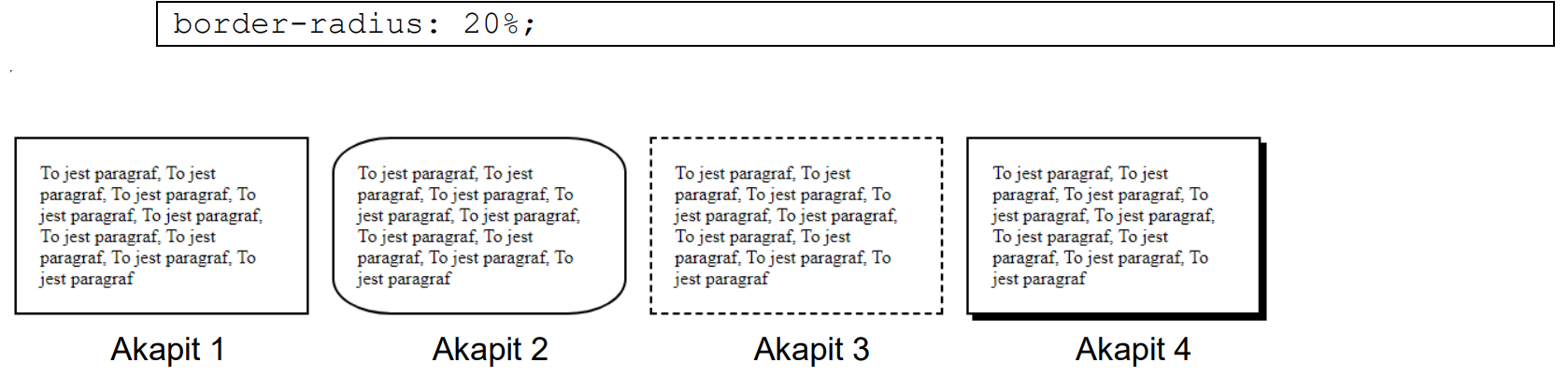
Pytanie 1
Jakie będzie działanie po naciśnięciu przycisku oznaczonego jako "niebieski", który uruchamia podany kod JavaScript?
| <p id="para1">Przykładowy tekst</p><p> i skrypt</p> <button onClick="changeColor('blue');">niebieski</button> <script type="text/javascript"> function changeColor(newColor) { var elem = document.getElementById("para1"); elem.style.color = newColor; } </script> |
A. Zmiana koloru tekstu "Przykładowy tekst" na niebieski
B. Zmiana barwy przycisku na niebieski
C. Zmiana koloru tekstu "Przykładowy tekst i skrypt" na niebieski
D. Zmiana koloru tekstu "i skrypt" na niebieski
Kod JavaScript przedstawiony w pytaniu definiuje funkcję changeColor która przyjmuje jeden argument newColor. Po wywołaniu funkcji przez kliknięcie przycisku funkcja ta używa metody document.getElementById aby pobrać element o identyfikatorze para1. Identyfikator ten jest przypisany do pierwszego elementu paragrafu zawierającego tekst Przykładowy tekst. Następnie w ramach tego elementu zmieniany jest kolor tekstu poprzez przypisanie newColor do właściwości style.color. W omawianym przypadku newColor przyjmuje wartość blue co oznacza że tekst Przykładowy tekst zmieni kolor na niebieski. Warto podkreślić że manipulacja DOM przy użyciu JavaScript jest powszechnie stosowaną techniką w tworzeniu dynamicznych interfejsów użytkownika. Używanie metod takich jak getElementById jest standardem ze względu na ich prostotę oraz efektywność w selekcji elementów HTML. W praktycznych zastosowaniach warto również pamiętać o zgodności ze standardami W3C oraz o możliwościach rozszerzenia za pomocą bibliotek takich jak jQuery które oferują jeszcze bardziej zaawansowane opcje manipulacji DOM.