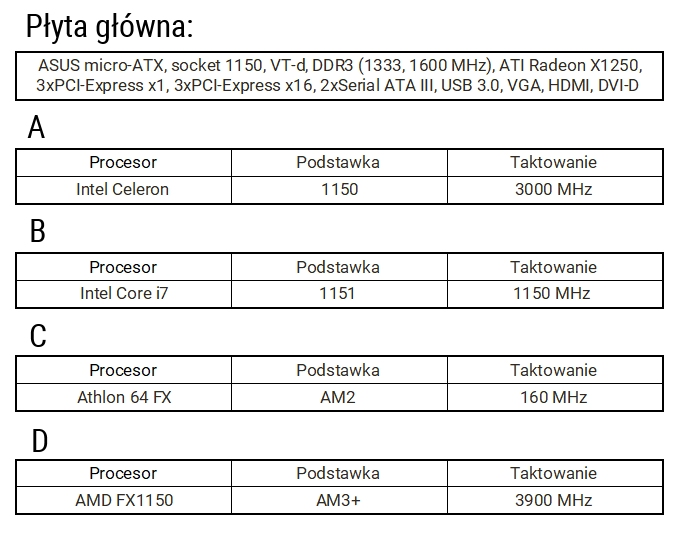
Pytanie 1
Jakie złącze jest potrzebne do podłączenia zasilania do CD-ROM?
A. Berg
B. 20-pinowe ATX
C. Mini-Molex
D. Molex
Wybór niewłaściwego złącza do podłączenia zasilania do CD-ROM może wynikać z nieporozumienia dotyczącego różnych typów złączy dostępnych na rynku komputerowym. Złącze Berg, powszechnie używane do zasilania dysków twardych w starszych komputerach, jest złączem 4-pinowym, ale jego zastosowanie jest ograniczone do urządzeń o niskim poborze mocy. W kontekście CD-ROM-a, które wymagają wyższego poziomu zasilania, złącze Berg nie dostarcza wystarczającej mocy. Mini-Molex, mimo że jest mniejsze niż standardowy Molex, również nie jest standardem w zasilaniu CD-ROM-ów, a jego zastosowanie jest bardziej typowe dla przenośnych urządzeń. Złącze 20-pinowe ATX, z drugiej strony, jest głównie używane do zasilania płyty głównej i nie ma zastosowania w bezpośrednim zasilaniu napędów optycznych. To złącze dostarcza zasilanie do komponentów takich jak procesory i pamięć RAM, ale nie ma odpowiednich napięć do zasilania CD-ROM-a. Wybór złącza do zasilania CD-ROM-a powinien być oparty na jego specyfikacji oraz wymaganiach zasilających, dlatego ważne jest zrozumienie różnic między tymi złączami oraz ich przeznaczeniem, aby uniknąć niezgodności i problemów z funkcjonowaniem sprzętu.