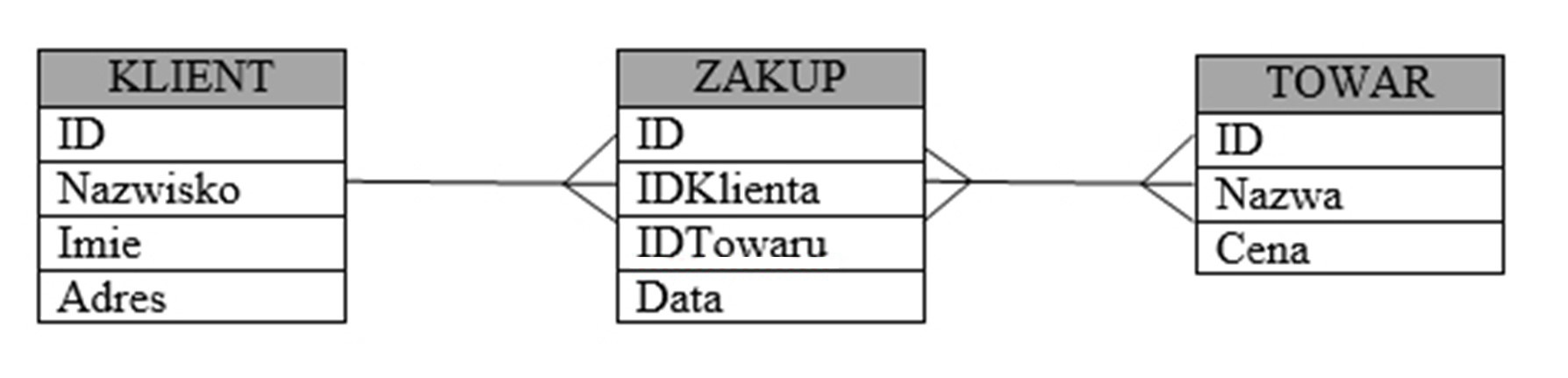
Pytanie 1
W bazie MySQL zdefiniowano podczas tworzenia tabeli pole
id int NOT NULL AUTO_INCREMENTWpis AUTO_INCREMENT oznacza, że
A. wartość kolumny id zostanie automatycznie przypisana przez system i będzie to przypadkowo wygenerowana liczba całkowita
B. możliwe jest wprowadzenie rekordu z dowolną wartością dla kolumny id
C. wartości tej kolumny będą automatycznie tworzone w trakcie dodawania nowego rekordu do bazy
D. kolumna id będzie mogła przyjmować wartości: NULL, 1, 2, 3, 4 i tak dalej
Wybór niepoprawnych odpowiedzi najczęściej wynika z niepełnego zrozumienia działania mechanizmu AUTO_INCREMENT w MySQL. Zgłoszenie, że dozwolone jest dodawanie rekordu z dowolną wartością pola id, jest błędne, ponieważ pole z AUTO_INCREMENT nie pozwala na wprowadzenie wartości ręcznie; to system bazy danych przydziela kolejne wartości. Ponadto, sugestia, że pole id może przyjmować wartość NULL jest również nieprawidłowa. W definicji pola 'id int NOT NULL AUTO_INCREMENT' zawiera się klauzula NOT NULL, co oznacza, że pole to nie może być puste - każdemu rekordowi musi być przypisana właściwa wartość. Inną mylną koncepcją jest stwierdzenie, że wartość pola id zostanie wygenerowana losowo. AUTO_INCREMENT nie generuje wartości losowych, lecz sekwencyjne, co oznacza, że wartości będą rosły o jeden w stosunku do ostatniego zarejestrowanego identyfikatora. Takie podejście zapewnia porządek i przewidywalność w bazie danych. Często zdarza się, że osoby korzystające z baz danych nie zdają sobie sprawy z tych mechanizmów, co prowadzi do mylnych wniosków. Zrozumienie zasad działania AUTO_INCREMENT jest kluczowe dla efektywnego projektowania baz danych oraz zapewnienia integralności danych.