Pytanie 1
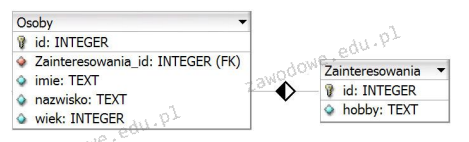
W języku PHP, aby nawiązać połączenie z bazą danych MySQL za pomocą biblioteki mysqli, wykorzystując podany kod, w miejscu parametru 'c' powinno się wpisać
| $a = new mysqli('b', 'c', 'd', 'e') |
A. lokalizację serwera bazy danych
B. hasło użytkownika
C. nazwę użytkownika
D. nazwę bazy danych
W języku PHP funkcja mysqli_connec lub konstruktor klasy mysqli służy do tworzenia połączeń z bazą danych MySQL. Ta funkcja wymaga podania kilku parametrów w określonej kolejności. Pierwszym parametrem jest lokalizacja serwera bazy danych zazwyczaj 'localhost' dla lokalnych serwerów. Drugim parametrem jest nazwa użytkownika. Jest to kluczowy element ponieważ pozwala na autoryzację i określa jakie operacje użytkownik może wykonywać na danej bazie danych. Zazwyczaj nazwa użytkownika to 'root' dla serwerów lokalnych ale na serwerach produkcyjnych często stosuje się inne konto użytkownika ze względów bezpieczeństwa. Trzecim parametrem jest hasło odpowiadające podanemu użytkownikowi zapewniające dodatkowy poziom bezpieczeństwa. Czwartym parametrem jest nazwa bazy danych do której użytkownik chce się połączyć. Dobrą praktyką jest korzystanie z plików konfiguracyjnych do przechowywania tych danych aby łatwo można było zarządzać różnymi środowiskami np. deweloperskim testowym i produkcyjnym bez konieczności modyfikacji kodu źródłowego. Prawidłowe zrozumienie tego mechanizmu jest kluczowe dla tworzenia bezpiecznych i stabilnych aplikacji webowych.