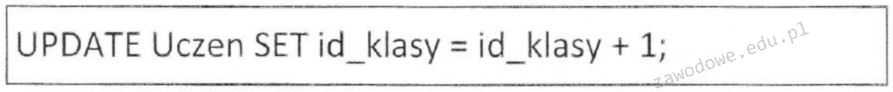Pytanie 1
W dołączonym fragmencie kodu CSS kolor został przedstawiony w formie

A. HSL
B. dziesiętnej
C. szesnastkowej
D. CMYK
Kolor zapisany w postaci szesnastkowej w CSS to popularny sposób definiowania barw na stronach internetowych. Szesnastkowy format koloru wykorzystuje sześć znaków, które są kombinacją cyfr oraz liter od A do F, poprzedzone znakiem hash (#). Każda para znaków reprezentuje wartość jednego z trzech podstawowych kolorów RGB: czerwonego, zielonego i niebieskiego. Na przykład kolor #008000 składa się z czerwonego o wartości 00, zielonego o wartości 80 i niebieskiego o wartości 00. Szesnastkowy zapis jest preferowany ze względu na swoją kompaktowość i zgodność ze standardami sieciowymi. W praktyce, projektanci często używają narzędzi do konwersji kolorów, aby uzyskać pożądane odcienie, co ułatwia zastosowanie odpowiednich wartości szesnastkowych w kodzie. Format ten pozwala także na tworzenie skróconych wersji, jak #FFF dla bieli. Jego użycie jest powszechne i dobrze zrozumiałe w branży, co czyni go uniwersalnym wyborem w projektach webowych.