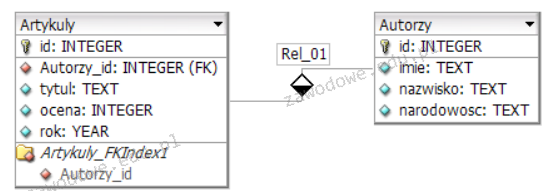
Pytanie 1
Poniższe zapytanie SQL ma na celu:
UPDATE Uczen SET id_klasy = id_klasy + 1;
A. ustawić wartość pola Uczen na 1
B. przypisać wartość kolumny id_klasy jako 1 dla wszystkich wpisów w tabeli Uczen
C. zwiększyć o jeden wartość kolumny id_klasy dla wszystkich wpisów w tabeli Uczen
D. zwiększyć o jeden wartość pola Uczen
Wybierając błędne odpowiedzi, można wpaść w pułapki związane z interpretacją polecenia SQL. Na przykład, stwierdzenie, że polecenie zwiększa wartość pola Uczen, jest mylące, ponieważ nie odnosi się do konkretnej kolumny. W SQL każde polecenie musi być precyzyjne, a używanie ogólnych terminów prowadzi do nieporozumień. Mówiąc o "ustawieniu na 1 wartości pola Uczen", mylnie sugeruje się, że wszystkie dane są resetowane do jednej wartości, co jest całkowicie błędne w kontekście podanego polecenia. Kolejną nieprawidłową koncepcją jest pomysł, iż polecenie ustawia wartość kolumny na 1 dla wszystkich rekordów. W rzeczywistości, aktualizuje ono istniejące wartości, zwiększając je o jeden, a nie ustawia ich na stałą wartość. Takie nieprecyzyjne zrozumienie języka SQL może prowadzić do katastrofalnych skutków w praktycznych zastosowaniach baz danych, w tym do utraty danych lub niepoprawnych aktualizacji, co jest sprzeczne z dobrymi praktykami zarządzania danymi. Kluczowe jest zrozumienie, że każdy element w SQL odgrywa istotną rolę, a nieprecyzyjność prowadzi do błędów, które mogą być czasochłonne do naprawienia. Z tego powodu, w pracy z SQL, należy zwracać znaczną uwagę na szczegóły oraz logiczną strukturę zapytań.