Pytanie 1
Na ilustracji przedstawiono
A. analizę poprawności kodu strony internetowej.
B. analizę ruchu sieciowego między serwerem a przeglądarką.
C. testy bezpieczeństwa strony.
D. testy funkcjonalne strony interenetowej.
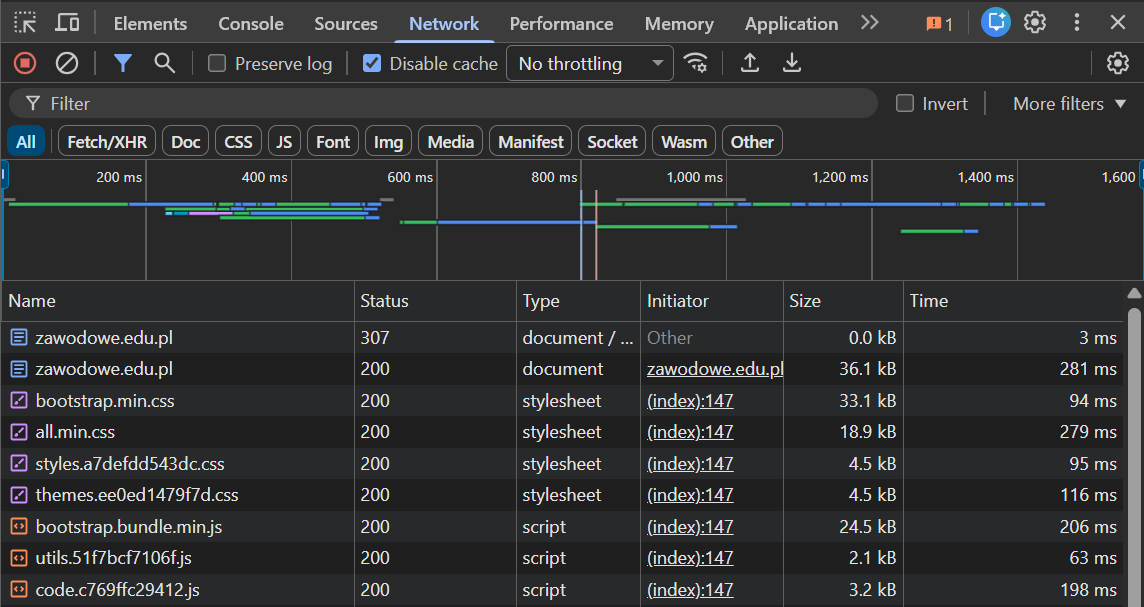
Na zrzucie ekranu widać kartę „Network” w narzędziach deweloperskich przeglądarki (DevTools). To właśnie tutaj podglądamy, jak wygląda ruch sieciowy pomiędzy przeglądarką a serwerem. Każdy wiersz listy to jedno żądanie HTTP/HTTPS: dokument HTML, arkusz CSS, skrypt JS, grafika, font itp. W kolumnach masz m.in. Name (adres zasobu), Status (kody odpowiedzi HTTP, np. 200, 307), Type (rodzaj zasobu), Size (wielkość odpowiedzi) oraz Time (czas pobierania). U góry widać wykres czasowy, który pokazuje, kiedy poszczególne żądania były wysyłane i jak długo trwało ich obsłużenie. To jest klasyczna analiza ruchu sieciowego między serwerem a przeglądarką, a nie testy funkcjonalne czy bezpieczeństwa. W praktyce takie narzędzie wykorzystuje się do diagnozowania problemów z wydajnością strony (np. które pliki ładują się najdłużej), do sprawdzania, czy wszystkie zasoby ładują się poprawnie (brak błędów 404, 500), do inspekcji nagłówków HTTP (np. cache-control, content-type, CORS), a także do podglądu zapytań AJAX / Fetch/XHR wysyłanych przez skrypty JavaScript. Moim zdaniem znajomość tej zakładki to absolutna podstawa pracy front-end developera i testera, bo pozwala szybko zweryfikować, co naprawdę dzieje się „pod maską” podczas ładowania strony i komunikacji klient–serwer. Dobre praktyki w branży zalecają regularne korzystanie z DevTools przy optymalizacji czasu ładowania, analizie błędów sieciowych oraz przy debugowaniu REST API czy komunikacji z backendem.