Pytanie 1
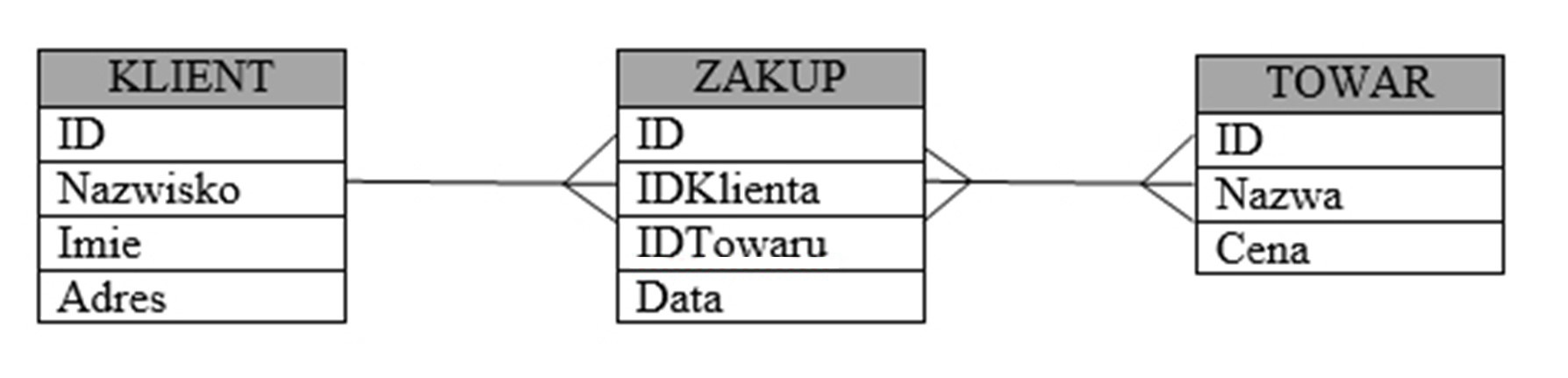
Jakie zapytanie należy zastosować, aby pokazać tylko imię, nazwisko oraz ulicę wszystkich mieszkańców?

A. SELECT * FROM Mieszkancy, Adresy ON Mieszkancy.id = Adresy.id
B. SELECT imie, nazwisko, ulica FROM Mieszkancy, Adresy ON Mieszkancy.Adresy_id = Adresy.id
C. SELECT imie, nazwisko, ulica FROM Mieszkancy JOIN Adresy ON Mieszkancy.Adresy_id = Adresy.id
D. SELECT * FROM Mieszkancy JOIN Adresy ON Adresy.id = Mieszkancy.Adresy.id
Prawidłowa odpowiedź wykorzystuje funkcję JOIN, aby połączyć tabele Mieszkancy i Adresy na podstawie wspólnego klucza, czyli Adresy_id z tabeli Mieszkancy i id z tabeli Adresy. Takie podejście jest zgodne z dobrymi praktykami baz danych, ponieważ zapewnia, że tylko powiązane wiersze są zwracane w wyniku. W zapytaniu SELECT imie, nazwisko, ulica FROM Mieszkancy JOIN Adresy ON Mieszkancy.Adresy_id = Adresy.id jasno określamy, że chcemy wyciągnąć tylko kolumny imie, nazwisko oraz ulica, co minimalizuje ilość przetwarzanych danych, a co za tym idzie, zwiększa wydajność. W rzeczywistych scenariuszach, takie zapytania są kluczowe w aplikacjach, gdzie konieczne jest uzyskanie pełnych danych dotyczących mieszkańców i ich adresów bez zbędnych informacji. Dobre praktyki SQL sugerują, aby zawsze wybierać tylko te kolumny, które są potrzebne, co pomaga w optymalizacji zasobów serwera i poprawie szybkości przetwarzania zapytań. JOIN jest preferowany nad starym stylem, jakim jest użycie przecinków i warunku w WHERE, z powodu lepszej czytelności i mniejszej podatności na błędy, co czyni kod bardziej zrozumiałym i łatwiejszym do utrzymania.