Pytanie 1
Strona internetowa powinna mieć zorganizowaną strukturę bloków. Aby osiągnąć ten układ, należy przypisać sekcjom odpowiednie właściwości w ten sposób:
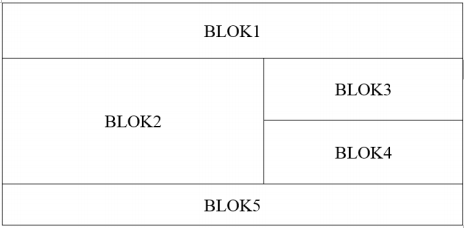
A. float jedynie dla bloków: 3, 4; clear dla bloku 5
B. float tylko dla bloku 2; clear dla bloków: 3, 4
C. float wyłącznie dla bloku 5; clear dla bloku 2
D. float tylko dla bloków: 2, 3, 4; clear dla bloku 5
Odpowiedź czwarta jest prawidłowa, ponieważ użycie właściwości CSS float dla bloków 2, 3 i 4 oraz właściwości clear dla bloku 5 odpowiada oczekiwanemu układowi strony. Float pozwala na ustawienie elementów obok siebie w poziomie. W tym przypadku blok 2, 3 i 4 będą umieszczone w jednej linii dzięki właściwości float: left. Blok 2 będzie zajmował więcej przestrzeni w pionie, co pozwala umieścić bloki 3 i 4 obok siebie. Blok 5 powinien znaleźć się poniżej, więc wymaga zastosowania właściwości clear: both, aby uniknąć zachodzenia na inne elementy pływające. Taki układ jest często stosowany w projektowaniu responsywnych stron internetowych, gdzie float umożliwia elastyczne dostosowanie się elementów do różnych szerokości ekranów. Warto pamiętać, że obecnie często używa się także display: flex lub grid jako nowocześniejszych sposobów układania elementów, jednak float wciąż znajduje zastosowanie w prostych układach. Zrozumienie, jak działa float i clear, jest kluczowe dla tworzenia poprawnych i estetycznych układów bloków na stronie internetowej.