Pytanie 1
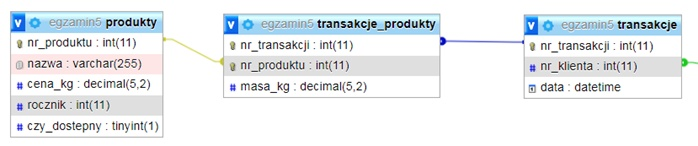
Na przedstawionej grafice widać fragment bazy danych. Jakie kwerendę należy zastosować, aby uzyskać nazwy produktów zakupionych przez klienta o id = 1?
A. SELECT nazwa FROM produkty JOIN transakcje_produkty JOIN transakcje WHERE nr_klienta = 1
B. SELECT nazwa FROM produkty JOIN transakcje ON nr_produktu = nr_klienta WHERE nr_klienta = 1
C. SELECT nazwa FROM produkty JOIN transakcje_produkty USING(nr_produktu) JOIN transakcje USING(nr_transakcji) WHERE nr_klienta = 1
D. SELECT nazwa FROM produkty JOIN transakcje_produkty USING(nr_produktu) WHERE nr_klienta = 1
Niepoprawne odpowiedzi wynikają z błędnego zrozumienia struktury bazy danych oraz sposobu łączenia tabel. Błędem w połączeniach JOIN jest nieprawidłowe określenie warunków łączenia tabel co prowadzi do niekompletnych lub błędnych wyników. W przypadku bazy danych relacyjnej kluczowe jest aby każda tabela była prawidłowo połączona przez klucz obcy co zapewnia integralność danych. Źle skonstruowane zapytania mogą powodować problemy wydajnościowe jak również zwracać niewłaściwe informacje co jest szczególnie problematyczne w środowisku produkcyjnym. Typowe błędy myślowe obejmują nieprawidłowe zrozumienie pojęcia klucza obcego jako mechanizmu łączącego tabele oraz błędne stosowanie klauzuli WHERE bez uwzględnienia pełnej relacji między tabelami. Również użycie niewłaściwych aliasów czy nieprecyzyjnych warunków może prowadzić do nieoptymalnych zapytań. Dlatego też ważne jest zrozumienie działania JOIN oraz jego wpływu na zapytania SQL aby móc skutecznie projektować systemy bazodanowe które są skalowalne i efektywne w działaniu.