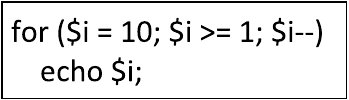Pytanie 1
Jaką wartość przyjmie zmienna a po wykonaniu poniższej sekwencji komend w PHP?
| $a = 1; $a++; $a += 10; --$a; |
A. 10
B. 11
C. 1
D. 12
Zmienna a początkowo jest ustawiona na wartość 1. Instrukcja $a++ to postinkrementacja co oznacza że pierwotna wartość zmiennej a jest użyta w bieżącym wyrażeniu a dopiero potem zwiększana. Po wykonaniu tej instrukcji a staje się 2. Następnie $a += 10 zwiększa wartość o 10 co daje nam 12. Ostatecznie instrukcja --$a to predekrementacja co oznacza że zmniejsza wartość przed użyciem w wyrażeniu. W efekcie końcowym a wynosi 11. W praktyce zrozumienie różnic między inkrementacją a dekrementacją jest kluczowe dla efektywnego kodowania zwłaszcza przy operacjach na licznikach w pętlach. Dobre praktyki w programowaniu zalecają świadome stosowanie post- i preinkrementacji oraz zrozumienie jak te operacje wpływają na logikę programu. Umiejętność przewidywania efektów tych operacji jest jedną z podstawowych kompetencji programistycznych która znacząco wpływa na jakość i niezawodność tworzonego oprogramowania. Warto także zwrócić uwagę na zachowanie tych operatorów w różnych językach programowania ponieważ mimo pewnych podobieństw zachowanie może się różnić