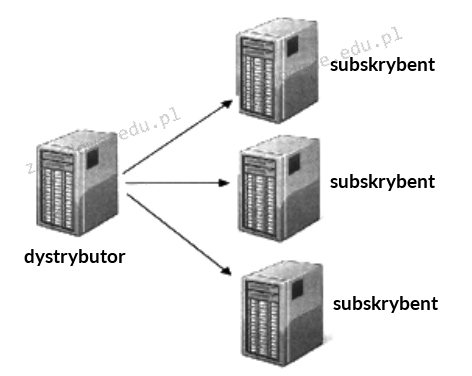
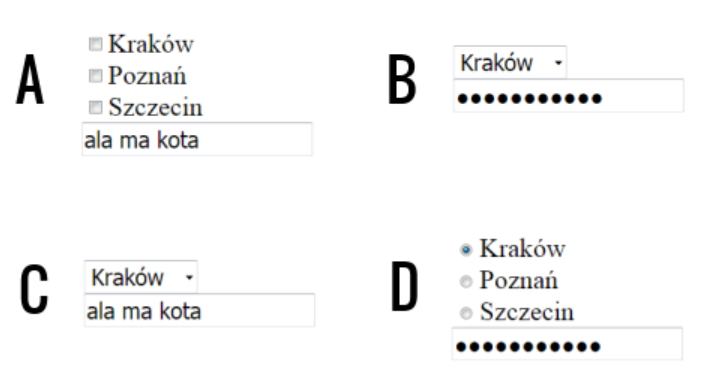
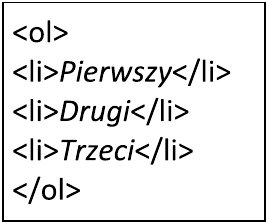Pytanie 1
W języku JavaScript następujący zapis: var napis1 = new napisy); ma na celu
A. stworzenie instancji obiektu napis1 klasy napisy
B. wywołanie metody dla obiektu napisy
C. stworzenie nowej klasy napis1
D. zadeklarowanie zmiennej napis1 oraz wywołanie funkcji, w której argumentem jest napis1
W podanym kodzie JavaScript mamy do czynienia z próbą utworzenia obiektu klasy 'napisy'. Operacja 'new' w JavaScript jest używana do instancjowania obiektów z funkcji konstrukcyjnych, które pełnią rolę klas. Przykład działania: jeśli mamy zdefiniowaną funkcję konstrukcyjną 'function napisy() { this.text = ''; }', to użycie 'var napis1 = new napisy();' stworzy nowy obiekt 'napis1', który będzie posiadał właściwość 'text'. Warto zwrócić uwagę, że 'napisy' musi być zdefiniowane jako funkcja konstrukcyjna, aby mogło być użyte w kontekście 'new'. Zrozumienie tego mechanizmu jest kluczowe w programowaniu obiektowym w JavaScript, gdzie klasy i obiekty odgrywają fundamentalną rolę w organizacji kodu. Aby lepiej zrozumieć działanie tego fragmentu, warto zapoznać się z dokumentacją dotyczącą obiektów i funkcji w JavaScript, co znajduje się w standardzie ECMAScript. Przykładowy kod ilustrujący tworzenie obiektu mógłby wyglądać tak: 'var napis1 = new napisy(); console.log(napis1.text);'.