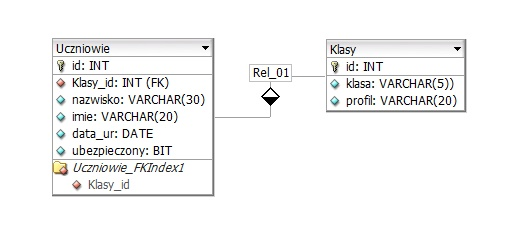
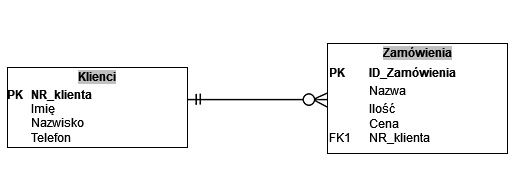
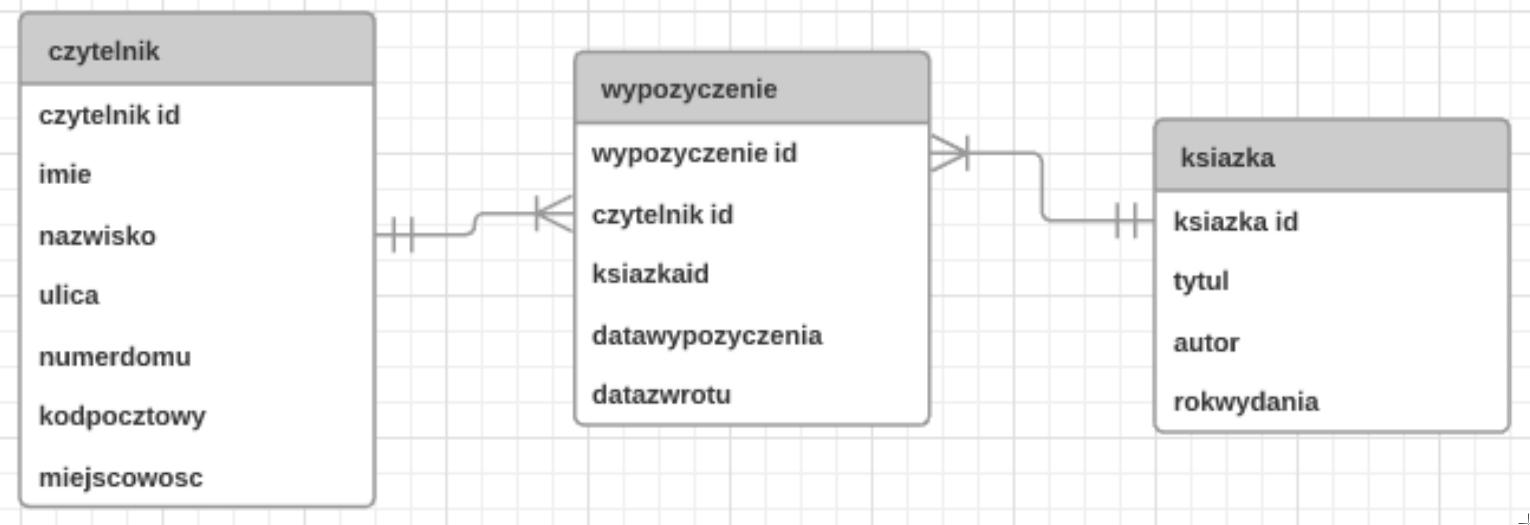
Pytanie 1
Podaj zapytanie SQL, które tworzy użytkownika sekretarka na localhost z hasłem zaq123?
A. CREATE USER `sekretarka`@`localhost` IDENTIFY "zaq123";
B. CREATE USER `sekretarka`@`localhost` IDENTIFIED BY 'zaq123';
C. CREATE USER `sekretarka`@`localhost` IDENTIFY BY `zaq123`;
D. CREATE USER 'sekretarka'@'localhost' IDENTIFIED `zaq123`;
Odpowiedź "CREATE USER `sekretarka`@`localhost` IDENTIFIED BY 'zaq123';" jest prawidłowa, ponieważ wykorzystuje poprawną składnię do tworzenia nowego użytkownika w systemie zarządzania bazą danych MySQL. Kluczowe jest użycie słowa kluczowego 'IDENTIFIED BY', które wskazuje, że podane hasło ('zaq123') ma być powiązane z nowym użytkownikiem. Wartości w apostrofach są odpowiednie dla łańcuchów tekstowych w SQL, co jest zgodne z dobrymi praktykami programowania w MySQL. W praktyce, tworzenie użytkowników z odpowiednimi uprawnieniami jest niezbędne do zarządzania dostępem do bazy danych oraz zapewnienia bezpieczeństwa. Dobrą praktyką jest stosowanie silnych haseł oraz regularne audyty kont użytkowników. Warto również zwrócić uwagę na konwencje nazewnictwa oraz ograniczenia w zakresie adresów IP, co ma znaczenie w kontekście bezpieczeństwa i zarządzania użytkownikami w systemie zarządzania bazą danych.