Pytanie 1
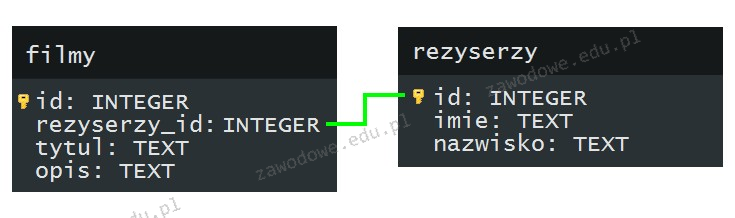
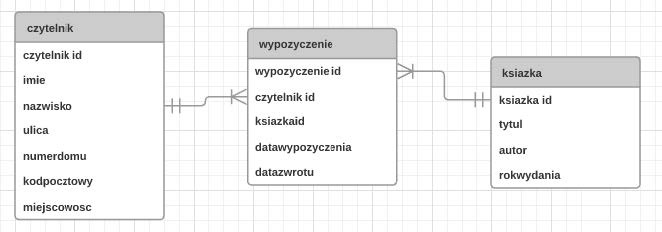
W przedstawionym diagramie bazy danych biblioteka, elementy: czytelnik, wypozyczenie i ksiazka są
A. atrybutami.
B. krotkami.
C. encjami.
D. polami.
W tym zadaniu kluczowe jest zrozumienie, jak na diagramie bazy danych odróżnić encje od pozostałych elementów modelu. Nazwy „czytelnik”, „wypozyczenie” i „ksiazka” to nie są pojedyncze dane, tylko typy obiektów, o których przechowujemy informacje. W relacyjnych bazach danych i w klasycznym modelu ER przyjmuje się, że takie prostokąty z nazwą u góry reprezentują encje, czyli odpowiedniki tabel. To jest punkt wyjścia do dalszego projektowania: określamy encje, ich atrybuty i relacje między nimi. Częsty błąd polega na myleniu encji z atrybutami. Atrybuty to cechy encji, czyli kolumny w tabeli, np. imie, nazwisko, tytul, autor, datawypozyczenia. One opisują konkretną encję, ale same w sobie nie są odrębnymi obiektami w modelu. Gdybyśmy uznali „czytelnik” albo „ksiazka” za atrybut, całkowicie zgubilibyśmy strukturę relacji i nie moglibyśmy poprawnie odwzorować zależności typu jeden-do-wielu czy wiele-do-wielu, które są standardem w dobrze zaprojektowanych bazach. Pojawia się też zamieszanie wokół krotek. Krotka (rekord, wiersz) to jedno konkretne wystąpienie encji, np. jeden konkretny czytelnik albo jedna konkretna książka w tabeli. Na diagramie logicznym nie pokazuje się pojedynczych krotek, tylko ogólny typ obiektu. Dlatego nazwy tabel nie mogą być krotkami – one reprezentują zbiór wszystkich możliwych rekordów danego typu. Z kolei pola to potoczna nazwa kolumn, a więc znowu mówimy o atrybutach, a nie o tabelach. Wiele osób używa słów „pola” i „atrybuty” zamiennie, co jest w miarę akceptowalne w luźnej rozmowie, ale w analizie modelu danych warto być precyzyjnym, bo inaczej łatwo pomylić poziom abstrakcji. Trzymając się dobrych praktyk projektowania relacyjnych baz danych, prostokąty z nazwami „czytelnik”, „wypozyczenie” i „ksiazka” interpretujemy jednoznacznie jako encje.