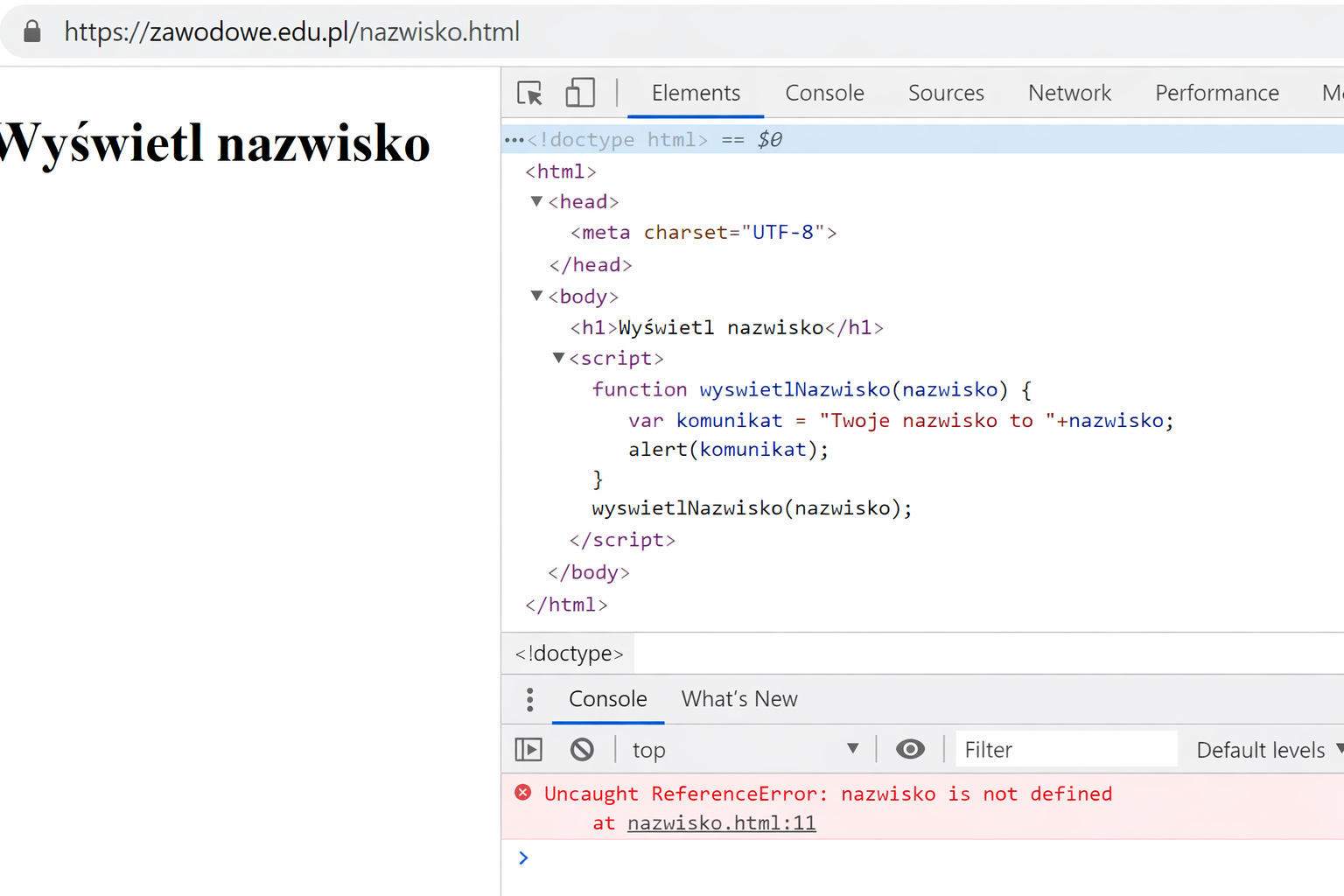
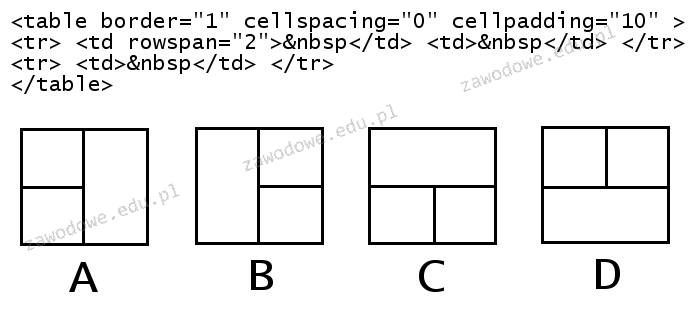
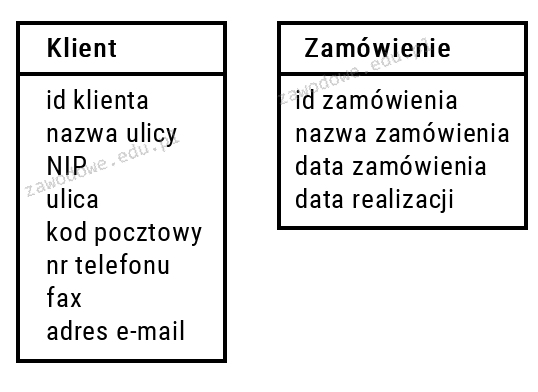
Pytanie 1
Poniższe zapytanie SQL ma na celu:
UPDATE Uczen SET id_klasy = id_klasy + 1;
A. ustawić wartość pola Uczen na 1
B. przypisać wartość kolumny id_klasy jako 1 dla wszystkich wpisów w tabeli Uczen
C. zwiększyć o jeden wartość pola Uczen
D. zwiększyć o jeden wartość kolumny id_klasy dla wszystkich wpisów w tabeli Uczen
Polecenie SQL "UPDATE Uczen SET id_klasy = id_klasy + 1;" jest poprawne, ponieważ wskazuje na aktualizację kolumny 'id_klasy' w tabeli 'Uczen'. Wartość kolumny dla każdego rekordu w tabeli zostanie zwiększona o jeden. Działanie to jest przydatne w sytuacjach, gdy chcemy zaktualizować dane, na przykład po przesunięciu uczniów do wyższej klasy w systemie edukacyjnym. Przy takim podejściu, wszyscy uczniowie w danym roku szkolnym mogą zostać automatycznie przeniesieni do następnej klasy bez konieczności edytowania rekordów pojedynczo, co zwiększa efektywność i zmniejsza ryzyko błędów. Ta praktyka jest zgodna z zasadami optymalizacji baz danych, gdzie operacje masowe są preferowane dla ich wydajności. Ponadto, dobrym nawykiem jest tworzenie kopii zapasowych przed przeprowadzeniem masowych aktualizacji, aby uniknąć nieodwracalnych zmian w przypadku błędów.