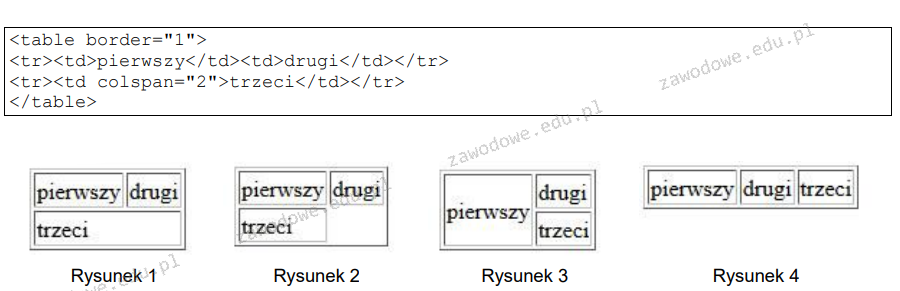
Pytanie 1
Jakie zadanie wykonuje funkcja napisana w JavaScript?
| function fun1(a,b) { if ( a % 2 != 0 ) a++; for(n=a; n<=b; n+=2) document.write(n); } |
A. wypisanie liczb parzystych w przedziale od a do b
B. sprawdzenie, czy liczba a jest liczbą nieparzystą; jeśli tak, to jej wypisanie
C. wypisanie wszystkich liczb w zakresie od a do b
D. zwrócenie parzystych wartości liczb od a do b
Analiza niepoprawnych odpowiedzi wymaga zrozumienia, dlaczego poszczególne opcje nie pasują do działania funkcji fun1. W pierwszym przypadku, opcja dotycząca sprawdzania, czy liczba a jest nieparzysta i jej wypisywania, nie jest zgodna z logiką funkcji. Chociaż funkcja sprawdza, czy a jest nieparzysta, to nie wypisuje jej, lecz zmienia ją na parzystą, co wskazuje, że jej celem nie jest wypisywanie liczby a, ale przygotowanie jej do dalszej iteracji. Wypisanie wszystkich liczb z przedziału od a do b również nie jest prawidłowe, ponieważ funkcja nie iteruje po wszystkich liczbach, lecz wyłącznie po liczbach parzystych. Warto zauważyć, że funkcja pomija wszystkie liczby nieparzyste, co wyklucza tę opcję. Kolejna możliwa odpowiedź sugeruje zwracanie wartości parzystych liczb od a do b, jednak funkcja nie wykorzystuje żadnej procedury zwracania wartości, a jej konstrukcja wskazuje na bezpośrednie wypisywanie wyników, co wyklucza tę możliwość. Typowy błąd myślowy to niepoprawne rozumienie działania pętli for oraz operacji wypisywania danych w kontekście przeglądarki internetowej, co jest istotne z punktu widzenia dynamicznych aplikacji webowych. Zrozumienie, jak działa operator modulo i jego rola w wyznaczaniu parzystości liczb, jest kluczowe dla poprawnego interpretowania takich fragmentów kodu. Wskazane jest również, aby programiści byli świadomi różnicy między wypisywaniem a zwracaniem wyników, co często prowadzi do nieporozumień w kontekście funkcji i metod w JavaScript i innych językach programowania.