Pytanie 1
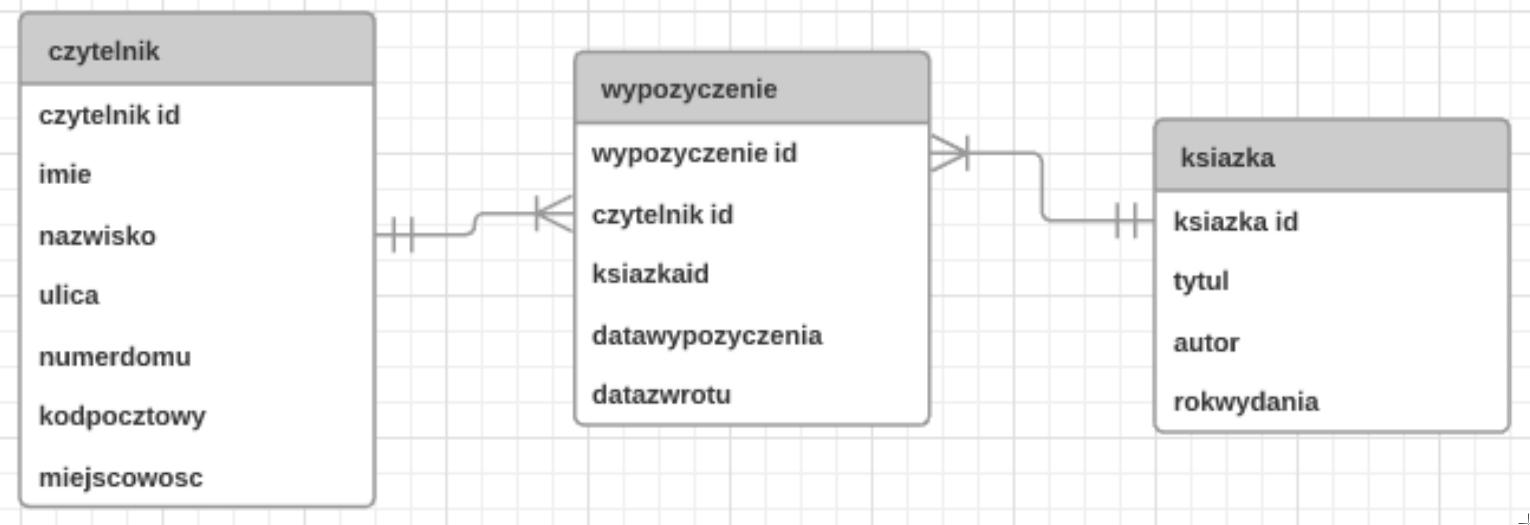
Z tabel Klienci oraz Uslugi należy wyodrębnić tylko imiona klientów oraz odpowiadające im nazwy usług, które kosztują więcej niż 10 zł. Kwerenda uzyskująca te informacje ma formę

A. SELECT imie, nazwa FROM klienci JOIN uslugi ON uslugi.id = uslugi_id
B. SELECT imie, nazwa FROM klienci JOIN uslugi ON uslugi.id = klienci.id
C. SELECT imie, nazwa FROM klienci JOIN uslugi ON uslugi.id = uslugi_id WHERE cena > 10
D. SELECT imie, nazwa FROM klienci, uslugi WHERE cena < 10
Pozostałe odpowiedzi zawierają istotne błędy w składni SQL oraz w interpretacji relacji między tabelami w bazie danych. Odpowiedź używająca WHERE cena < 10 jest błędna, ponieważ warunek ten wybiera usługi tańsze niż 10 zł, co jest sprzeczne z wymogami zadania. Innym błędem jest użycie niepoprawnego połączenia ON bez odpowiedniego dopasowania kluczy. Użycie klauzuli JOIN bez precyzyjnego określenia relacji, jak w przypadku ON uslugi.id = klienci.id, nie odzwierciedla rzeczywistego związku danych, co prowadzi do błędów logicznych w wynikach. Prawidłowe korzystanie z JOIN wymaga zrozumienia struktury bazy danych oraz relacji między tabelami. Właściwe połączanie tabel z wykorzystaniem klucza obcego jest kluczową praktyką, która zapewnia integralność danych i optymalizację zapytań. Ponadto, brak zastosowania warunków filtracyjnych lub nieodpowiednie ich użycie prowadzi do zwracania niekompletnych lub niepoprawnych danych. Wiedza o strukturze bazy danych oraz umiejętność stosowania poprawnych zapytań SQL są niezbędne dla osób zajmujących się projektowaniem i zarządzaniem bazami danych. Praktyczne doświadczenie w stosowaniu tych umiejętności jest kluczowe dla zapewnienia skuteczności oraz wydajności operacji w bazach danych. Poprawne zapytania są podstawą każdej operacji bazodanowej, zarówno w kontekście codziennych operacji, jak i skomplikowanych analiz danych.