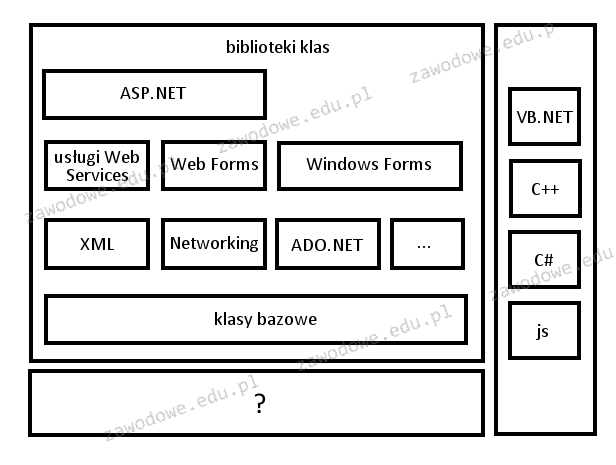
Pytanie 1
Aby w JavaScript wykonać wymienione kroki, należy w znaczniku <script> umieścić kod
| 1. Wyświetlić okno do wpisania wartości z poleceniem "Podaj kwalifikację: ", następnie po zatwierdzeniu 2. Umieścić napis na stronie internetowej, gdzie w miejscu kropek znajduje się wartość pobrana z okna "Kwalifikacja: ..." |
A. A << prompt("Podaj kwalifikację: "); document.write("Kwalifikacja: " + A);
B. A = prompt("Podaj kwalifikację: "); document.write("Kwalifikacja: ".A);
C. A = prompt("Podaj kwalifikację: "); document.write("Kwalifikacja: " + A);
D. A = alert("Podaj kwalifikację: "); document.write("Kwalifikacja: " + A);
Gratulacje, wybrałeś prawidłową odpowiedź! Kiedy chcemy wykonać interakcje z użytkownikiem poprzez okno dialogowe w JavaScript, używamy funkcji 'prompt()'. Ta funkcja wyświetla okno dialogowe z komunikatem tekstowym, polem do wprowadzania danych i przyciskami OK / Anuluj. Wartość wprowadzona przez użytkownika jest następnie zwracana przez funkcję 'prompt()'. W tym przypadku, używamy funkcji 'prompt()' do pobrania kwalifikacji od użytkownika. Następnie, używamy funkcji 'document.write()' do wyświetlenia zdobytej kwalifikacji na stronie internetowej. Operator '+' jest używany do łączenia łańcuchów znaków (stringów) w JavaScript, co pozwala na połączenie wartości wprowadzonej przez użytkownika z komunikatem 'Kwalifikacja: '. Pamiętaj, że choć 'document.write()' jest łatwym sposobem na wyświetlanie wyników na stronie, jest to metoda zarezerwowana głównie do testowania i debugowania, a nie do użytku produkcyjnego, ze względu na możliwość nadpisania zawartości strony.