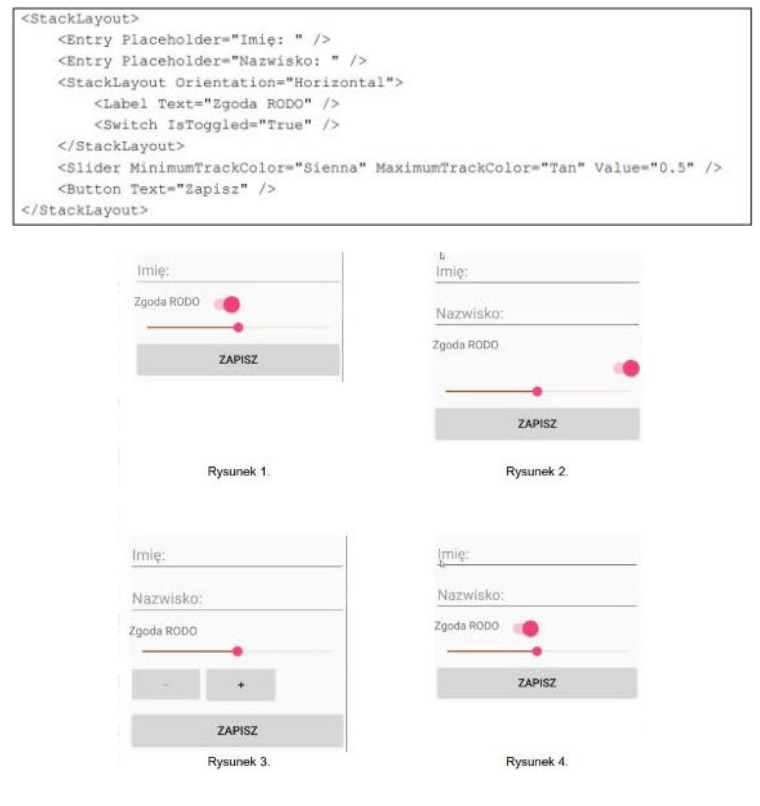
Pytanie 1
Zaproponowany fragment kodu w Android Studio realizuje metodę nasłuchującą do obsługi wydarzenia:
przycisk = (Button) findViewById(R.id.yes_button); przycisk.setOnClickListener(new View.OnClickListener() { ... });
A. wybór daty
B. zmiany stanu kontrolki Switch
C. zmiany w polu tekstowym
D. naciśnięcia przycisku
Metoda OnClickListener, to coś, co na pewno warto znać, gdy pracujesz z aplikacjami na Androida. Gdy użytkownik klika przycisk, wywoływana jest metoda onClick. I tu możesz zrobić różne rzeczy, jak na przykład przejść do innego ekranu, zapisać dane albo uruchomić jakąś akcję w tle. To jest dobry przykład wzorca projektowego zwanego Delegacja, który pomaga oddzielić to, co widzisz w interfejsie, od tego, co dzieje się w aplikacji. Dzięki temu łatwiej zarządzać kodem i wprowadzać zmiany. Fajnie jest, gdy logikę umieszczasz w osobnych metodach, bo wtedy testowanie całej aplikacji staje się prostsze. Przykłady? Możesz na przykład użyć OnClickListenera, żeby zrobić logowanie po kliknięciu przycisku lub wysłać formularz. Pamiętaj też, żeby unikać ciężkich operacji w metodzie onClick, żeby aplikacja działała płynnie.