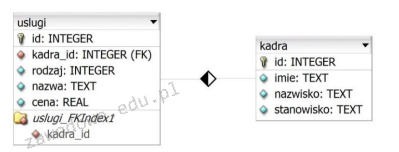
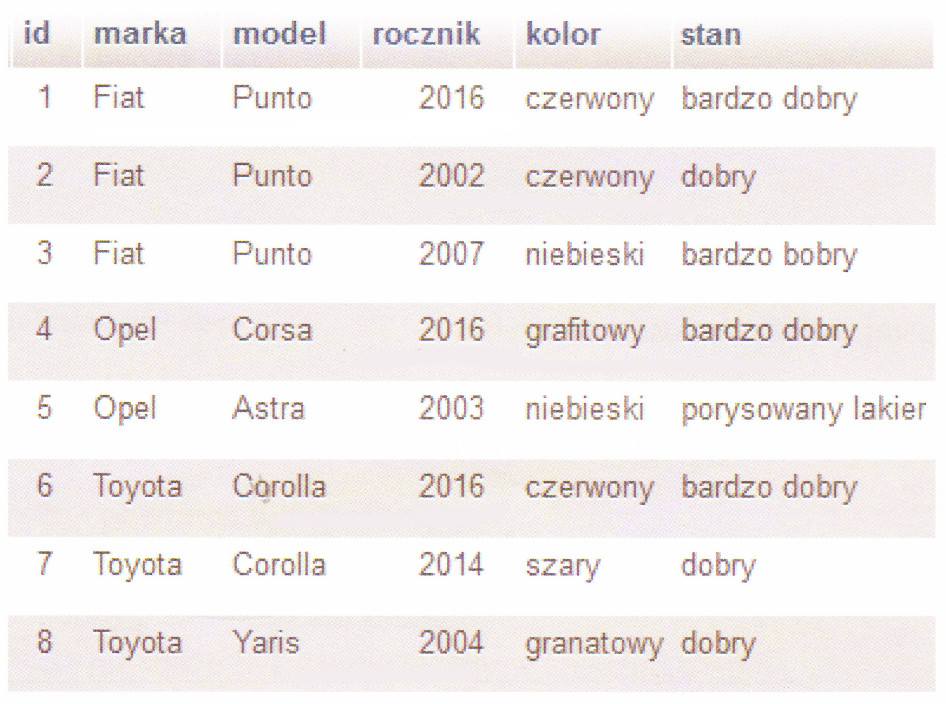
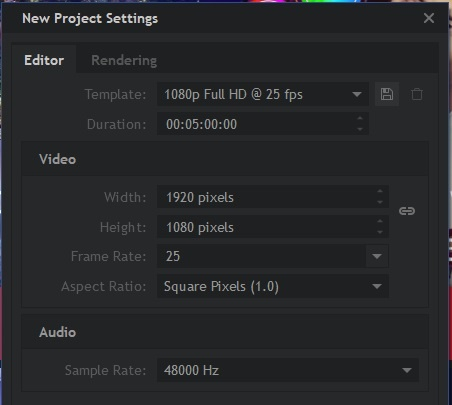
Pytanie 1
Jaki będzie rezultat po uruchomieniu podanego skryptu?
class Owoc { function __construct() { echo "test1"; } function __destruct() { echo "test2"; } } $gruszka = new Owoc();
A. Pojawi się wyłącznie tekst „test2”
B. Nie pojawi się żaden tekst
C. Pojawią się oba teksty: „test1” i „test2”
D. Pojawi się jedynie tekst „test1”
Wybór błędnych odpowiedzi może wynikać z tego, że nie do końca rozumiesz, jak działają konstruktory i destruktory w programowaniu obiektowym. Nie jest tak, że nie ma żadnego napisu, bo nawet jeżeli nie stworzysz obiektu, to przy końcu skryptu destruktor powinien się uruchomić i wtedy wyświetli się 'test2'. Tak że, gdy mówisz, że tylko 'test1' się pokaże, to nie bierzesz pod uwagę, co się dzieje po zakończeniu skryptu. I to, co napisałeś, że tylko 'test2' się wyświetli, też nie jest prawdą, bo konstruktor musi być wywołany, kiedy robi się obiekt. Zrozumienie tych wszystkich spraw jest naprawdę ważne, by dobrze zarządzać danymi w aplikacjach, zwłaszcza w większych projektach, gdzie jest masa obiektów i różne interakcje między nimi.