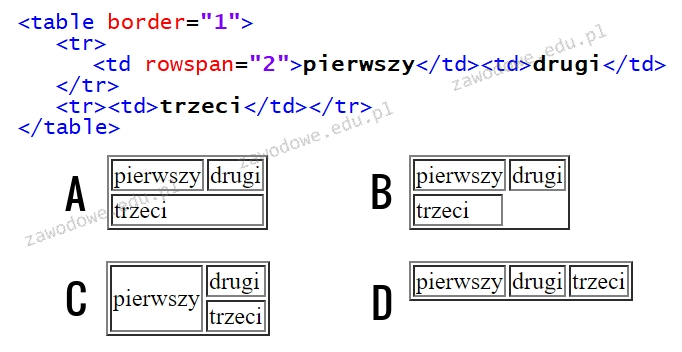
Pytanie 1
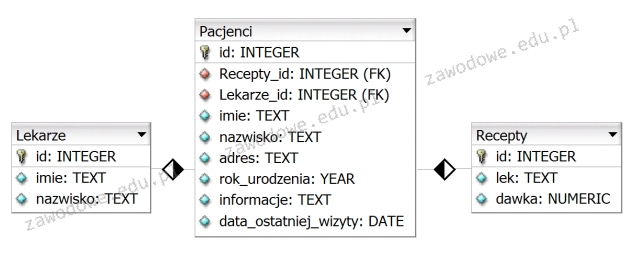
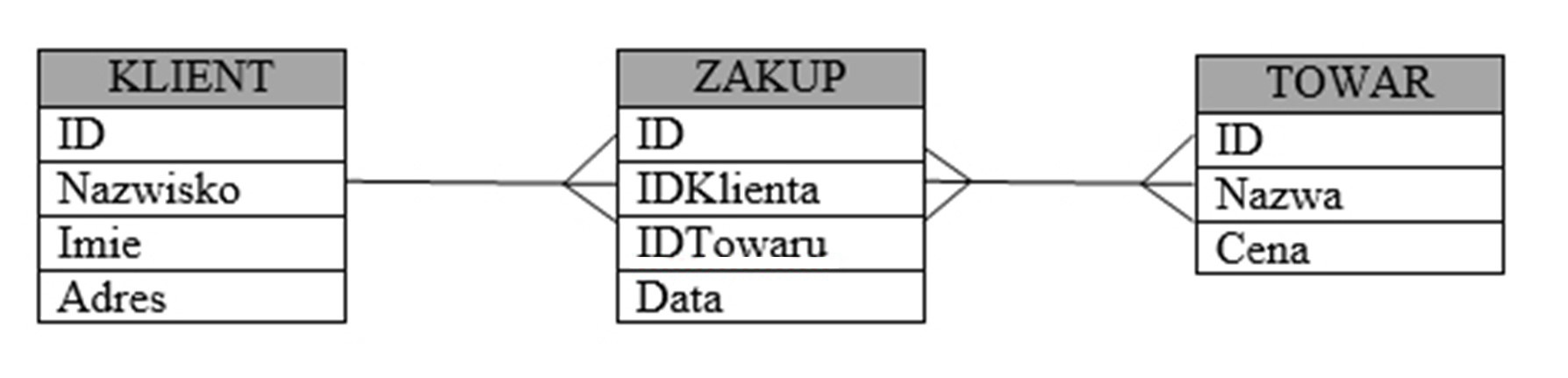
W której notacji diagramów ER został zapisany model związków encji przedstawiony na ilustracji?
A. Bachmana.
B. Martina.
C. Min-Max.
D. Chena.
Prawidłowa odpowiedź to notacja Martina. Na diagramie widać bardzo charakterystyczne cechy tej notacji: encje są przedstawione jako prostokąty z nagłówkiem wypełnionym innym kolorem (tu: ciemnoszary pasek z nazwą encji KLIENT, ZAKUP, TOWAR), a pod spodem w formie tabelki wypisane są atrybuty, jeden pod drugim. Klucz główny jest po prostu pierwszym atrybutem na liście (ID), bez dodatkowych ozdobników typu podkreślenie czy elipsa, co jest typowe właśnie dla podejścia Martina, zorientowanego na projektowanie relacyjnej bazy danych. Związki między encjami są rysowane liniami z tzw. crow’s foot ("kurzą łapką") po stronie encji wielokrotnej, a po stronie encji pojedynczej mamy prostą kreskę. Na ilustracji dokładnie to widać: ZAKUP jest encją pośredniczącą, a relacje KLIENT–ZAKUP i TOWAR–ZAKUP mają klasyczną symbolikę notacji Martina. W praktyce, w wielu narzędziach CASE (np. w starszych wersjach ERwin, PowerDesigner, Visio z szablonem Database Model Diagram) domyślny styl ERD jest właśnie bardzo zbliżony do notacji Martina. Taki diagram jest od razu „bliski” strukturze fizycznej tabel w SQL, więc łatwo go przełożyć na CREATE TABLE, klucze obce i indeksy. Z mojego doświadczenia w firmach produkcyjnych i w małych software house’ach notacja Martina jest często używana przy projektach, gdzie liczy się szybkie przejście z modelu koncepcyjnego do modelu logicznego i fizycznego, bez zbyt rozbudowanej symboliki teoretycznych ER-ów. Dlatego rozpoznanie tej notacji po wyglądzie encji-tabelek i crow’s foot jest bardzo praktyczną umiejętnością przy pracy z bazami danych.