Pytanie 1
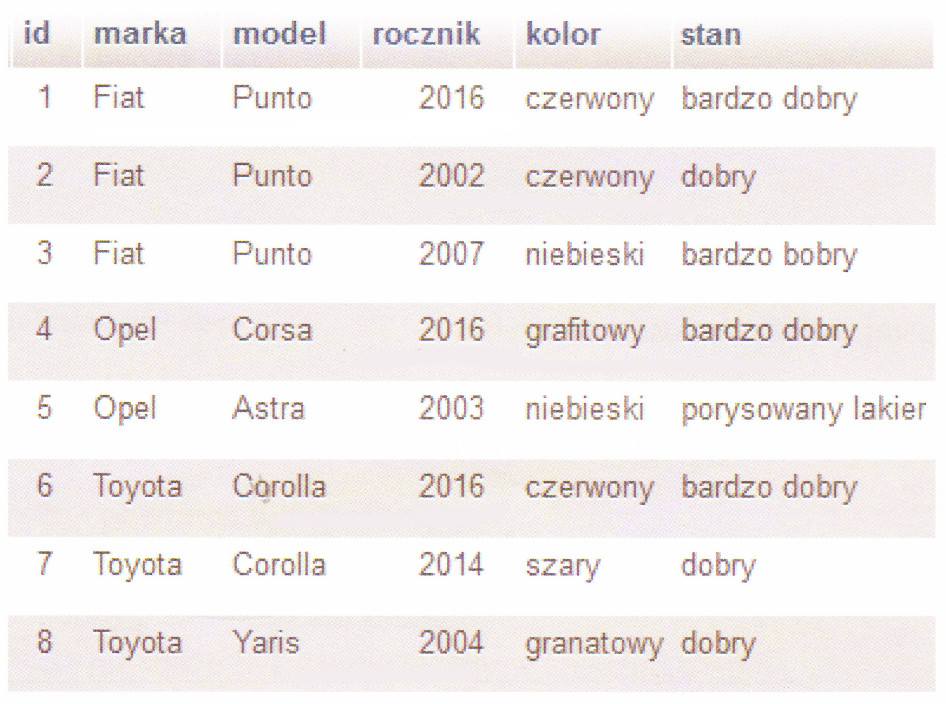
Na zaprezentowanej tabeli dotyczącej samochodów wykonano zapytanie SQL SELECT ```SELECT model FROM samochody WHERE rocznik=2016;``` Jakie wartości zostaną zwrócone w wyniku tego zapytania?
A. Fiat, Opel, Toyota
B. Punto, Corsa, Astra, Corolla, Yaris
C. Punto, Corsa, Corolla
D. Czerwony, grafitowy
Zapytanie SQL, które podałeś, czyli SELECT model FROM samochody WHERE rocznik=2016, jest zaprojektowane tak, żeby wyciągnąć z tabeli samochody wszystkie modele aut z rocznika 2016. To ogranicza wynik tylko do tych modeli, które spełniają ten właśnie warunek. Patrząc na dostarczoną tabelę, widzimy, że modele z rocznika 2016 to Punto, Corsa i Corolla. Więc z tego zapytania otrzymamy tylko te trzy modele. W realnym świecie, zapytania SQL są mega przydatne przy filtrowaniu danych w bazach. Zrozumienie, jak pisać zapytania SELECT, jest naprawdę ważne, zwłaszcza dla analityków i administratorów. Dobrze jest znać zasady budowania zapytań, żeby były one jasne i precyzyjne, bo to pozwala lepiej zarządzać i analizować dane. Ta wiedza to podstawa w analizie danych, gdzie umiejętność wyciągania odpowiednich informacji jest kluczowa do podejmowania dobrych decyzji biznesowych.