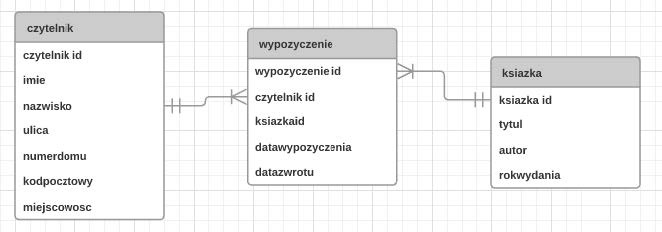
Pytanie 1
Aby stworzyć relację typu jeden do wielu, w tabeli reprezentującej stronę "wiele", konieczne jest zdefiniowanie
A. klucza sztucznego odnoszącego się do kluczy podstawowych obu tabel
B. klucza obcego wskazującego na klucz podstawowy tabeli reprezentującej stronę "jeden"
C. klucza obcego odnoszącego się do klucza obcego tabeli reprezentującej stronę "jeden"
D. klucza podstawowego odnoszącego się do klucza podstawowego tabeli po stronie "jeden"
Aby utworzyć relację jeden do wielu w bazach danych, kluczowym elementem jest właściwe zdefiniowanie klucza obcego. Klucz obcy w tabeli po stronie 'wiele' musi wskazywać na klucz podstawowy tabeli po stronie 'jeden'. Taki układ pozwala na powiązanie wielu rekordów z jednego tabeli z jednym rekordem w drugiej tabeli. Na przykład, w systemie zarządzania zamówieniami, tabela 'Klienci' może mieć klucz podstawowy 'ID_Klienta', podczas gdy tabela 'Zamówienia' może mieć klucz obcy 'ID_Klienta', który odnosi się do 'ID_Klienta' w tabeli 'Klienci'. Dzięki temu jedno ID klienta może być powiązane z wieloma zamówieniami. W praktyce, implementacja relacji jeden do wielu jest niezwykle przydatna w normalizacji bazy danych, co pomaga zminimalizować redundancję i poprawić integralność danych. Zgodnie z normami ACID, takie powiązania zapewniają, że operacje na danych są atomowe, spójne, izolowane i trwałe, co jest kluczowe dla niezawodności baz danych.