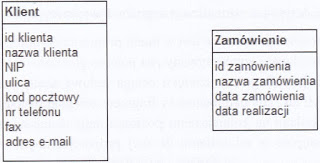
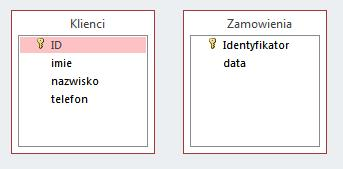
Pytanie 1
Proces przetwarzania sygnału wejściowego w czasie, wykorzystujący zasadę superpozycji, jest związany z filtrem
A. liniowym
B. o skończonej odpowiedzi impulsowej
C. przyczynowym
D. niezmiennym w czasie
Wybór odpowiedzi związanej z filtrami przyczynowymi, niezmiennymi w czasie i o skończonej odpowiedzi impulsowej może prowadzić do nieporozumień w kontekście filtracji sygnałów. Filtr przyczynowy, chociaż może być liniowy, niekoniecznie musi spełniać wszystkie założenia dotyczące superpozycji, ponieważ jego odpowiedź impulsowa ogranicza się do przeszłych wartości sygnału, co może wprowadzać dodatkowe zniekształcenia w analizie sygnałów. Stosowanie filtrów niezmiennych w czasie w kontekście superpozycji również wymaga ostrożności, ponieważ mogą one wprowadzać zmiany w amplitudzie i fazie sygnałów, co prowadzi do złożonych interakcji. Z kolei filtry o skończonej odpowiedzi impulsowej (FIR) są typem filtru liniowego, ale nie zawsze są przyczynowe; można je zaprojektować jako filtry nieprzyczynowe, co podważa ich użyteczność w kontekście rzeczywistych zastosowań przetwarzania sygnałów. Warto zauważyć, że w praktyce, projektowanie filtrów wymaga zrozumienia i analizy zarówno ich właściwości liniowych, jak i nieliniowych, a także wpływu na jakość przetwarzanych sygnałów. Kluczowe jest również uwzględnienie spektrum sygnału oraz jego cech, co jest zgodne z najlepszymi praktykami inżynieryjnymi, aby uzyskać optymalne wyniki w aplikacjach inżynieryjnych.