Pytanie 1
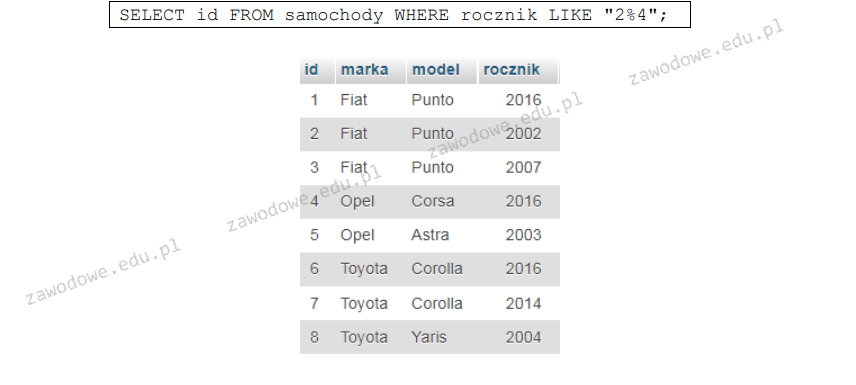
W tabeli mieszkancy znajdują się dane o osobach z całej Polski. Aby zliczyć, ile różnych miast jest zawartych w tej tabeli, należy wykonać kwerendę
A. SELECT COUNT(miasto) FROM mieszkancy;
B. SELECT COUNT(miasto) FROM mieszkancy DISTINCT;
C. SELECT COUNT(DISTINCT miasto) FROM mieszkancy;
D. SELECT DISTINCT miasto FROM mieszkancy;
Brak odpowiedzi na to pytanie.
Wyjaśnienie poprawnej odpowiedzi:
Wybrana kwerenda SELECT COUNT(DISTINCT miasto) FROM mieszkancy; jest poprawna, ponieważ pozwala na zliczenie unikalnych miast w tabeli mieszkancy. Funkcja DISTINCT eliminuje duplikaty, co oznacza, że tylko różne wartości miasto będą brane pod uwagę w procesie zliczania. Użycie COUNT w połączeniu z DISTINCT jest standardową praktyką w SQL, która zapewnia dokładne wyniki przy analizie danych. Taka metoda jest szczególnie przydatna w przypadku dużych zbiorów danych, gdzie wiele rekordów może odnosić się do tego samego miasta. Na przykład, jeśli mamy 1000 rekordów, z których 200 dotyczy Warszawy, 300 Krakowa oraz 500 Gdańska, kwerenda zwróci wynik 3, ponieważ tylko trzy różne miasta zostały uwzględnione. Tego typu zapytania są powszechne w raportach analitycznych, gdzie istotne jest zrozumienie dystrybucji danych oraz identyfikacja różnych kategorii w zbiorze, co jest niezbędne dla podejmowania decyzji biznesowych.
Wybrana kwerenda SELECT COUNT(DISTINCT miasto) FROM mieszkancy; jest poprawna, ponieważ pozwala na zliczenie unikalnych miast w tabeli mieszkancy. Funkcja DISTINCT eliminuje duplikaty, co oznacza, że tylko różne wartości miasto będą brane pod uwagę w procesie zliczania. Użycie COUNT w połączeniu z DISTINCT jest standardową praktyką w SQL, która zapewnia dokładne wyniki przy analizie danych. Taka metoda jest szczególnie przydatna w przypadku dużych zbiorów danych, gdzie wiele rekordów może odnosić się do tego samego miasta. Na przykład, jeśli mamy 1000 rekordów, z których 200 dotyczy Warszawy, 300 Krakowa oraz 500 Gdańska, kwerenda zwróci wynik 3, ponieważ tylko trzy różne miasta zostały uwzględnione. Tego typu zapytania są powszechne w raportach analitycznych, gdzie istotne jest zrozumienie dystrybucji danych oraz identyfikacja różnych kategorii w zbiorze, co jest niezbędne dla podejmowania decyzji biznesowych.