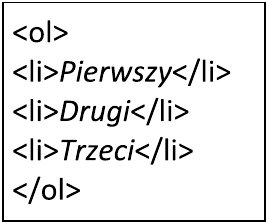Pytanie 1
W CSS zapis w postaci ```h1::first-letter{color:red;}``` spowoduje, że kolor czerwony będzie dotyczył
A. tekstów nagłówka pierwszego poziomu
B. pierwszej litery nagłówka pierwszego poziomu
C. pierwszej litery nagłówka drugiego poziomu
D. pierwszej linii akapitu
Zapis CSS h1::first-letter {color: red;} odnosi się do selektora pseudo-elementu first-letter, który jest używany do stylizacji pierwszej litery bloku tekstowego w nagłówkach. W tym wypadku, gdy selektor jest zastosowany do elementu h1, oznacza to, że kolor pierwszej litery nagłówka pierwszego stopnia (h1) zostanie zmieniony na czerwony. Pseudo-element first-letter działa tylko dla elementów blokowych, takich jak nagłówki, akapity czy listy. W praktyce, jeśli w dokumencie HTML mamy element <h1> z tekstem, np. 'Witaj świecie', to wyłącznie litera 'W' zostanie wyświetlona w kolorze czerwonym. To podejście jest zgodne ze standardami CSS, które definiują pseudo-elementy jako specyficzne fragmenty dokumentu, które można stylizować niezależnie od reszty zawartości. Warto również zauważyć, że stosowanie takich selektorów pozwala na uzyskanie bardziej złożonych efektów wizualnych bez konieczności modyfikacji struktury HTML. Umożliwia to projektantom stron internetowych większą elastyczność i kontrolę nad estetyką treści.