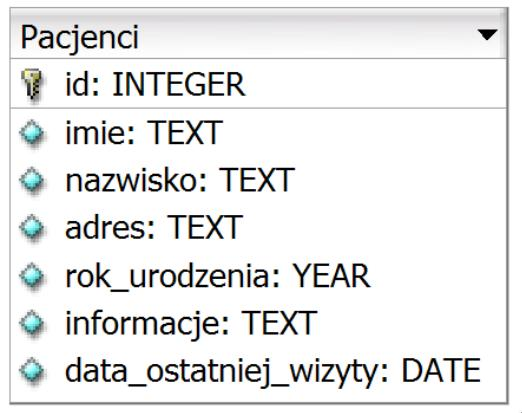
Pytanie 1
W języku SQL operator arytmetyczny odpowiadający reszcie z dzielenia to
A. &
B. ||
C. /
D. %
Operator arytmetyczny modulo, czyli ten %, to coś, co moim zdaniem jest naprawdę przydatne w SQL. Używamy go do obliczania reszty z dzielenia, co pokazuje na przykład taki kod: 'SELECT 10 % 3;', który zwraca 1. Chodzi o to, że 10 dzielone przez 3 to 3, a reszta to właśnie 1. To może być super pomocne, kiedy chcemy sprawdzić, czy liczba jest parzysta czy nie. Na przykład, możemy użyć takiego zapytania: 'SELECT CASE WHEN 5 % 2 = 0 THEN 'Parzysta' ELSE 'Nieparzysta' END;' i dostaniemy 'Nieparzysta'. Operator modulo przydaje się też w programowaniu, na przykład do tworzenia cykli lub rozdzielania danych w algorytmach. Dobrze jest pamiętać, że używając tego operatora w SQL, warto mieć na uwadze czytelność kodu. Szczególnie przy większych bazach danych, gdzie to ma znaczenie.