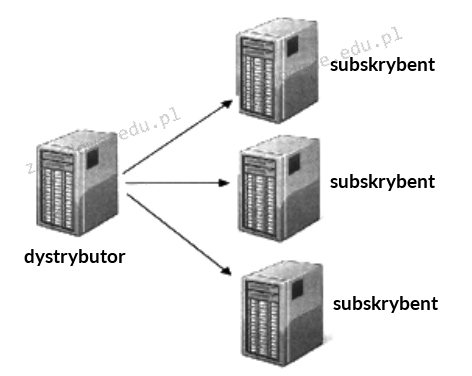
Pytanie 1
Który z poniższych fragmentów kodu HTML sformatuje tekst zgodnie z wymaganiami? (zauważ, że słowo "stacji" jest wyświetlane w większej czcionce niż pozostałe słowa w tej linii)

A. Odpowiedź 2: B
B. Odpowiedź 4: D
C. Odpowiedź 1: A
D. Odpowiedź 3: C
Odpowiedź B jest prawidłowa ponieważ używa znacznika big do zwiększenia rozmiaru czcionki dla słowa stacji wewnątrz paragrafu. Znacznik big jest standardowym sposobem na zwiększenie tekstu w HTML chociaż obecnie rekomendowane jest stosowanie CSS do takich stylizacji co pozwala na oddzielenie treści od prezentacji. Przykładowo można użyć CSS w stylu inline lub w oddzielnym arkuszu stylów aby uzyskać ten sam efekt co zwiększa elastyczność i spójność projektu. Warto pamiętać że HTML5 wprowadza pewne zmiany i deprecjonuje niektóre znaczniki co wymaga ciągłego aktualizowania wiedzy dewelopera. Znacznik big mimo że działa w większości przeglądarek może być mniej przewidywalny w przyszłości w porównaniu z CSS. Rozdzielenie stylów od struktury dokumentu jest dobrą praktyką programistyczną co ułatwia zarządzanie kodem oraz poprawia dostępność stron internetowych. Pamiętaj by regularnie analizować i aktualizować swoje projekty zgodnie z najnowszymi standardami HTML i CSS.

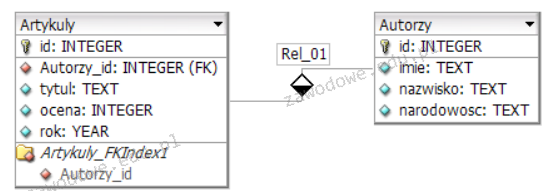
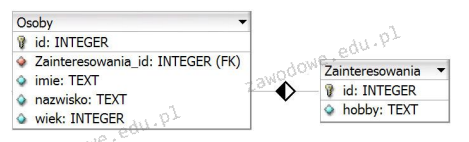
 ``` Jeżeli rysunek.png nie zostanie odnaleziony, przeglądarka:
``` Jeżeli rysunek.png nie zostanie odnaleziony, przeglądarka: