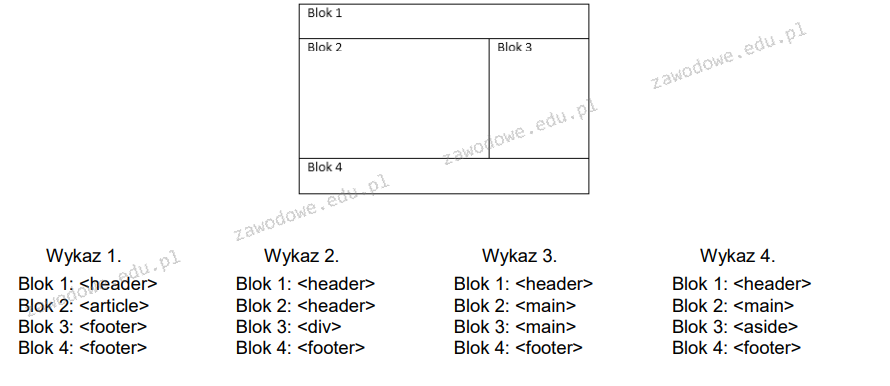
Pytanie 1
Które z poniższych twierdzeń o definicji funkcji pokazanej w ramce jest prawdziwe?
| function czytajImie(){ var imie=null; do { imie=prompt("podaj imie: "); if (imie.length<3) alert("wprowadzony tekst jest niepoprawny"); } while(imie.length<3); } |
A. Funkcja zawiera pętlę, która powtarza się 3 razy
B. Tekst będzie wczytywany do czasu podania liczby większej niż 3
C. Pętla zostanie uruchomiona tylko raz
D. Wczytanie tekstu zakończy się, gdy tekst będzie miał co najmniej 3 znaki
Funkcja czytajImie zawiera pętlę do-while która działa dopóki długość wprowadzonego ciągu znaków jest mniejsza niż 3 co oznacza że zakończenie pętli nastąpi gdy użytkownik wprowadzi tekst o długości co najmniej 3 znaków W praktyce oznacza to że funkcja wymaga od użytkownika podania imienia które będzie miało przynajmniej trzy znaki co jest powszechną praktyką podczas walidacji danych wejściowych w celu zapewnienia minimalnej ilości informacji Pętla do-while jest szczególnie przydatna w sytuacjach gdy musimy zagwarantować przynajmniej jedno wykonanie bloku kodu co tutaj pozwala na przynajmniej jednorazowe wywołanie okna prompt do wprowadzenia danych Tego typu walidacja jest podstawą podczas programowania interfejsów użytkownika gdzie poprawność i kompletność danych wejściowych jest kluczowa dla dalszego przetwarzania danych Warto również zauważyć że stosowanie tego rodzaju pętli w kontekście walidacji danych zwiększa użyteczność aplikacji poprzez zapewnienie że dane są zgodne z wymaganiami przed ich dalszym przetwarzaniem