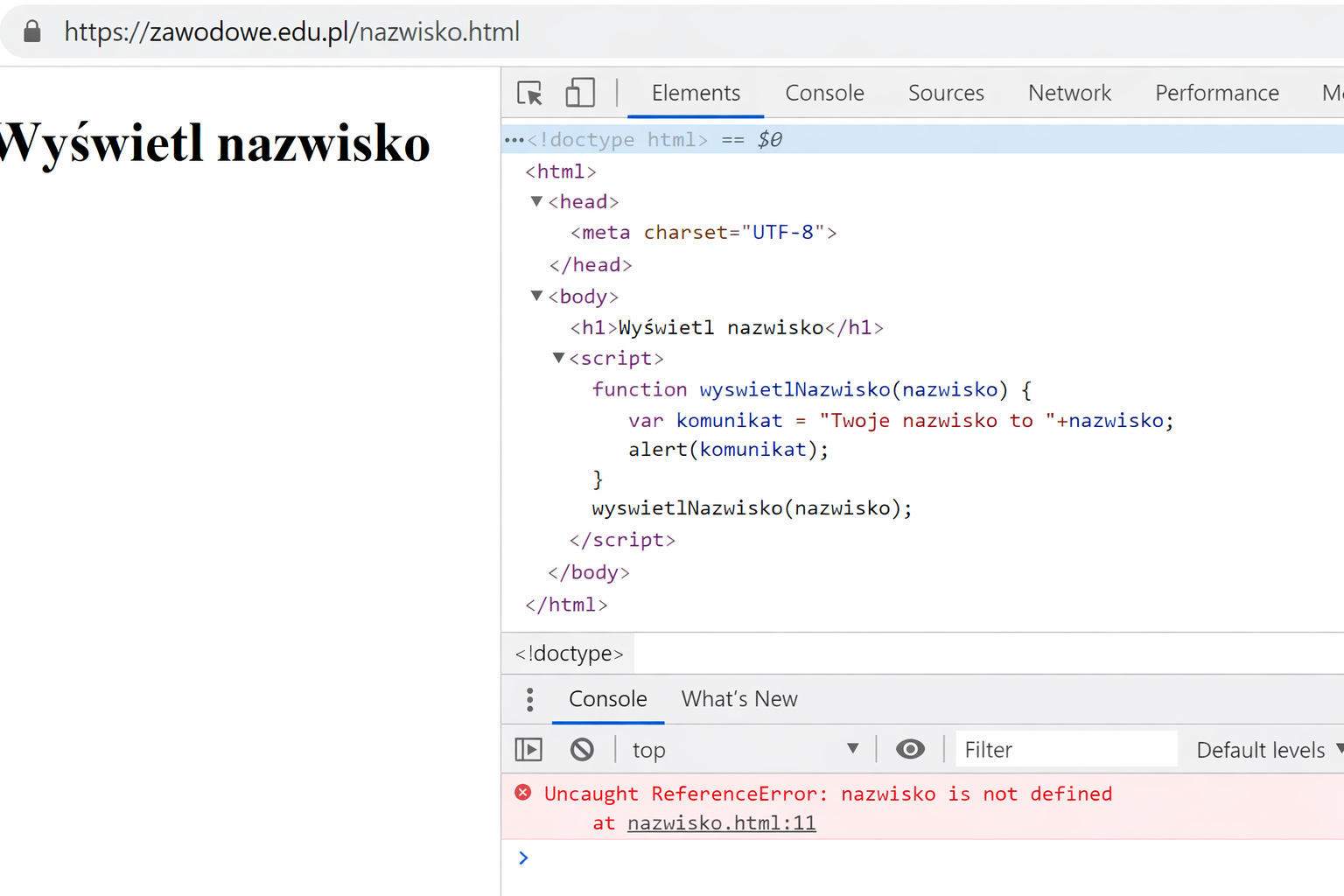
Pytanie 1
Jaki zapis w HTML służy do określenia kodowania znaków w dokumencie?
A. <charset="UTF-8">
B. <meta charset="UTF-8">
C. <meta encoding="UTF-8">
D. <encoding="UTF-8">
Poprawna odpowiedź to <meta charset="UTF-8">, która jest standardowym sposobem deklaracji kodowania znaków w dokumentach HTML. Użycie tego tagu w sekcji <head> dokumentu HTML informuje przeglądarki internetowe o tym, jakie znaki będą używane w danym dokumencie, co jest kluczowe dla prawidłowego wyświetlania treści. Deklaracja 'UTF-8' jest szczególnie powszechna, ponieważ obsługuje wiele różnych znaków i symboli z różnych języków, co czyni ją uniwersalnym wyborem dla większości stron internetowych. Przykłady zastosowań obejmują strony wielojęzyczne, gdzie ważne jest, aby tekst został prawidłowo wyświetlony bez błędów z powodu nieodpowiedniego kodowania. Zgodnie z najlepszymi praktykami w branży, zawsze zaleca się umieszczanie tego tagu na początku sekcji <head> dokumentu, aby zapewnić, że wszystkie elementy strony będą renderowane zgodnie z zamierzeniem twórcy. Użycie odpowiedniego kodowania znaków jest również istotne z punktu widzenia SEO, ponieważ wyszukiwarki mogą mieć problemy z indeksowaniem treści, jeśli kodowanie jest nieprawidłowo ustawione.