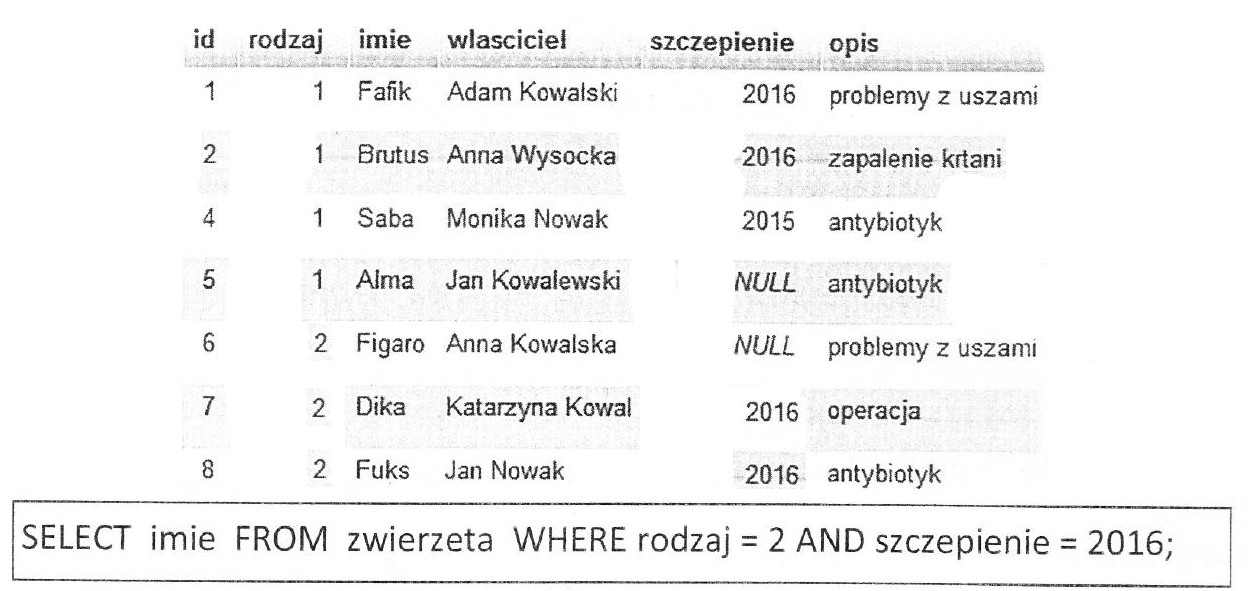
Pytanie 1
W języku PHP wyniki zapytania z bazy danych zostały pobrane przy użyciu polecenia mysql_query(). Aby uzyskać dane w postaci wierszy z tej zwróconej kwerendy, należy użyć polecenia:
A. mysql_field_len()
B. mysql_fetch_lengths()
C. mysql_fetch_row()
D. mysql_list_fields()
Funkcja mysql_fetch_row() to naprawdę ważne narzędzie w PHP, które pomaga w pracy z wynikami zapytań SQL. Kiedy wykonasz zapytanie za pomocą mysql_query(), dostajesz zestaw wyników, który można traktować jak tablicę. Używając mysql_fetch_row(), możesz pobrać jeden wiersz danych z tego zestawu, a to przychodzi w formie tablicy numerycznej. To bardzo przydatne, szczególnie gdy chcesz przejść przez wszystkie wiersze, które zwraca zapytanie. Na przykład, przy wyświetlaniu danych w HTML. Super jest to, że ta funkcja jest prosta w użyciu i działa efektywnie, dlatego tak wielu programistów ją ceni. Pamiętaj, żeby zawsze zabezpieczać zapytania przed SQL Injection. Możesz to zrobić, stosując przygotowane zapytania (prepared statements) albo funkcje, jak mysqli_query() z mysqli_fetch_row(). Warto też wiedzieć, że jeśli nie ma już więcej wierszy do pobrania, to mysql_fetch_row() zwróci false. Można to wykorzystać do kontrolowania pętli w kodzie, co jest przydatne.