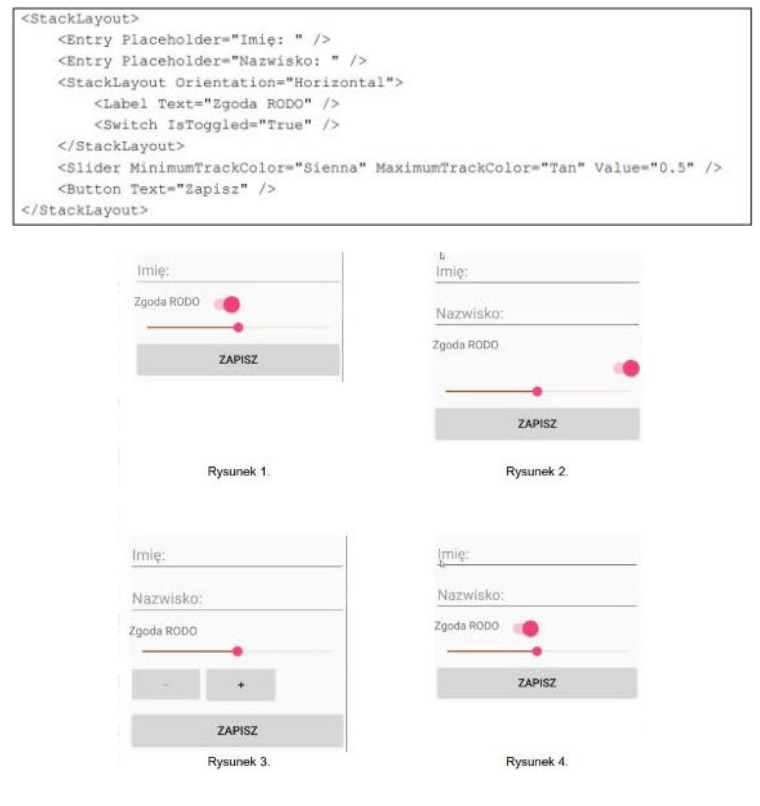
Pytanie 1
Oznaczenie ochrony przeciwpożarowej przedstawione na symbolu wskazuje na

A. system alarmowy przeciwpożarowy
B. przełącznik zasilania
C. rozdzielnię elektryczną
D. punkt remote release
Ten symbol jednoznacznie wskazuje na ręczny ostrzegacz pożarowy, będący kluczowym elementem systemu alarmowego przeciwpożarowego. W praktyce taki przycisk znajdziesz w korytarzach szkół, biur czy dużych hal, zwykle przy wyjściach ewakuacyjnych. Po naciśnięciu wywołuje on alarm w całym obiekcie, pozwalając na szybką reakcję służb oraz ewakuację osób znajdujących się w strefie zagrożenia. Moim zdaniem zrozumienie działania i lokalizacji ręcznych ostrzegaczy jest absolutnie fundamentalne dla bezpieczeństwa pożarowego każdego budynku. Zgodnie z normą PN-EN 54-11 oraz wytycznymi Państwowej Straży Pożarnej, oznaczenie to musi być dobrze widoczne, z wyraźną, czerwoną barwą tła i prostym, czytelnym symbolem. Praktyka pokazuje, że w sytuacjach krytycznych ludzie dużo szybciej reagują na jednoznaczne oznaczenia graficzne niż na same napisy. Właśnie dlatego tak bardzo przykłada się wagę do poprawnej widoczności i rozmieszczenia tych znaków. Sam system alarmowy przeciwpożarowy, którego częścią są takie przyciski, jest podstawą nie tylko ochrony ludzi, ale też minimalizowania strat materialnych, bo pozwala na natychmiastowe powiadomienie odpowiednich służb. Warto zapamiętać, że ręczne ostrzegacze są regularnie testowane podczas przeglądów PPOŻ i ich prawidłowe oznakowanie to wymóg prawny oraz element dobrej praktyki branżowej.