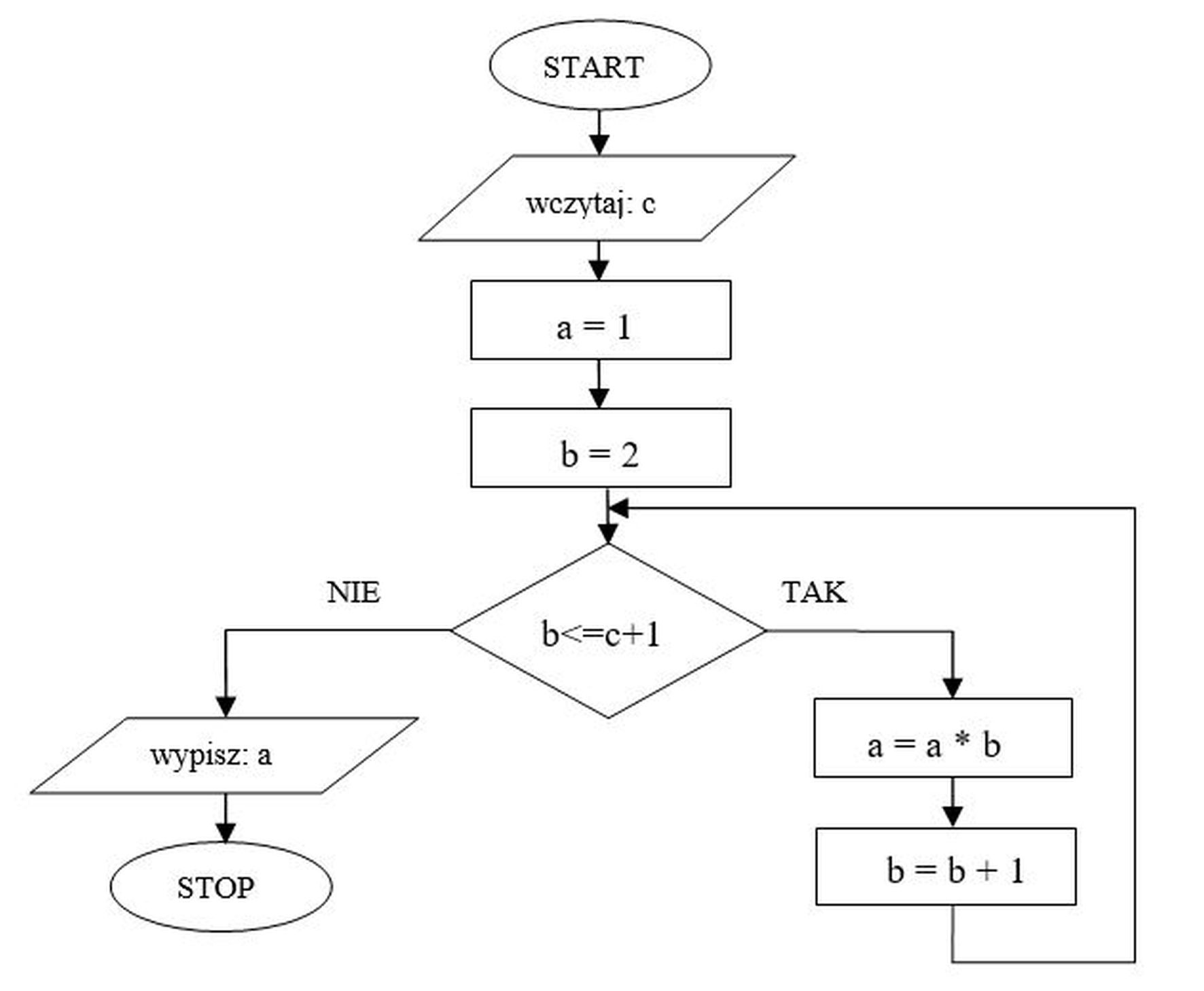
Pytanie 1
Jaką wartość przyjmie zmienna a po wykonaniu poniższej sekwencji komend w PHP?
| $a = 1; $a++; $a += 10; --$a; |
A. 12
B. 11
C. 1
D. 10
Początkowa wartość zmiennej a wynosi 1. Częstym błędem jest niewłaściwe zrozumienie działania operatorów inkrementacji i dekrementacji. W przypadku operatora postinkrementacji $a++ najpierw używana jest aktualna wartość zmiennej a a dopiero po tym następuje jej zwiększenie co daje 2. To zamieszanie może prowadzić do błędnego przekonania że wartość zmiennej wzrasta natychmiast co jest nieprawidłowe. Następnie instrukcja $a += 10 zwiększa wartość zmiennej o 10 co w rzeczywistości daje 12. Powszechnym błędem jest niedostateczne zrozumienie jak działają przypisania z dodawaniem co może skutkować nieoczekiwanymi wynikami. Ostatnia instrukcja --$a jest predekrementacją co oznacza że wartość zmiennej zmniejsza się przed jej użyciem co ostatecznie prowadzi do wartości 11. Często myli się to z postdekrementacją gdzie wartości byłyby używane przed zmniejszeniem co wpływa na kolejność operacji. Zrozumienie różnicy między pre- i post-operatorami jest niezbędne dla precyzyjnego przewidywania wyników kodu. Uwaga na te subtelności jest kluczowa dla unikania błędów logicznych w programowaniu i zapewnienia poprawnego działania aplikacji