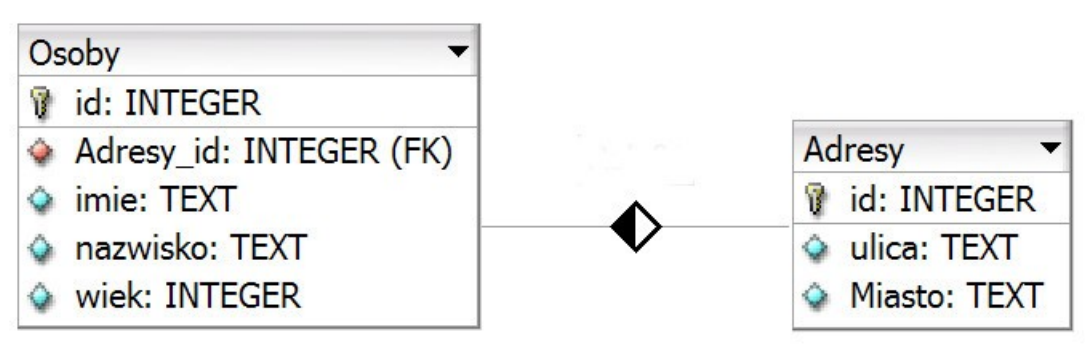
Pytanie 1
Dana jest tabela ksiazki z polami: tytul, autor, cena (typu liczbowego). Aby kwerenda SELECT wybrała tylko tytuły, dla których cena jest mniejsza od 50 zł, należy zapisać
A. SELECT ksiazki FROM tytul WHERE cena < '50 zł';
B. SELECT * FROM ksiazki WHERE cena < 50;
C. SELECT tytul FROM ksiazki WHERE cena < 50;
D. SELECT tytul FROM ksiazki WHERE cena > '50 zł';
Prawidłowa odpowiedź wybiera dokładnie to, o co chodzi w treści zadania: tylko kolumnę tytul z tabeli ksiazki, ale tylko dla tych rekordów, gdzie cena jest mniejsza niż 50. Składnia SELECT tytul FROM ksiazki WHERE cena < 50; jest zgodna ze standardowym SQL i pokazuje dobrą praktykę – pobieramy tylko te dane, które są nam potrzebne, zamiast używać SELECT *. Dzięki temu zapytanie jest lżejsze, szybsze i czytelniejsze, co w większych projektach ma naprawdę duże znaczenie. Moim zdaniem warto zwrócić uwagę na kilka elementów. Po pierwsze, w klauzuli SELECT podajemy konkretne nazwy kolumn (tu: tytul), nie nazwę tabeli. Po drugie, w FROM podajemy dokładnie nazwę tabeli, z której korzystamy (ksiazki). Po trzecie, warunek WHERE cena < 50 poprawnie porównuje wartość liczbową, bo kolumna cena ma typ liczbowy, więc nie używamy tu cudzysłowów ani żadnych „zł” w środku. W praktyce podobny wzorzec stosuje się cały czas, np.: SELECT tytul, autor FROM ksiazki WHERE cena <= 30; żeby dostać tańsze książki, albo SELECT tytul FROM ksiazki WHERE cena BETWEEN 20 AND 40; gdy interesuje nas konkretny przedział. W profesjonalnych aplikacjach webowych taka precyzja w definiowaniu zapytań SQL jest podstawą: ułatwia optymalizację, indeksowanie kolumn (np. indeks na kolumnie cena przyspiesza filtrowanie w WHERE) i minimalizuje przesyłanie niepotrzebnych danych między bazą a aplikacją. Dobra praktyka jest też taka, żeby dostosowywać typy danych: skoro cena jest liczbą, to porównujemy ją z liczbą, bez jednostek, a formatowanie typu „50 zł” robimy później w warstwie prezentacji, np. w PHP, JavaScript albo w szablonach widoków.