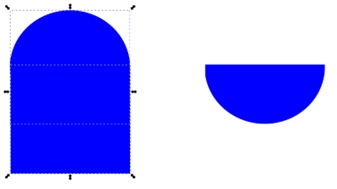
Pytanie 1
Aby usunąć nienaturalne wygładzanie ukośnych krawędzi w grafice rastrowej, czyli tak zwane schodkowanie, konieczne jest wykorzystanie filtru
A. antyaliasingu
B. szumu
C. gradientu
D. pikselizacji
Brak odpowiedzi na to pytanie.
Wyjaśnienie poprawnej odpowiedzi:
Antyaliasing to technika stosowana w grafice rastrowej, która ma na celu wygładzenie krawędzi obiektów, co z kolei redukuje efekt schodkowania. Schodkowanie, zwane również jagged edges, to zjawisko, w którym krawędzie linii wyglądają na poszarpane i nienaturalne, co jest szczególnie zauważalne przy nachylonych liniach lub krzywych. Antyaliasing działa na zasadzie wygładzania krawędzi poprzez mieszanie kolorów pikseli na granicy obiektu z kolorami pikseli tła, co tworzy iluzję płynności. Przykładem zastosowania antyaliasingu jest grafika komputerowa w grach, gdzie zapewnia on bardziej realistyczny obraz, a także przy renderowaniu grafik wektorowych do rastrowych. W standardach branżowych, takich jak OpenGL i DirectX, zastosowanie antyaliasingu jest zalecane, aby poprawić jakość wizualną i doświadczenia użytkowników. Zastosowanie technik takich jak MSAA (Multisample Anti-Aliasing) lub FXAA (Fast Approximate Anti-Aliasing) jest powszechną praktyką w nowoczesnych aplikacjach graficznych.
Antyaliasing to technika stosowana w grafice rastrowej, która ma na celu wygładzenie krawędzi obiektów, co z kolei redukuje efekt schodkowania. Schodkowanie, zwane również jagged edges, to zjawisko, w którym krawędzie linii wyglądają na poszarpane i nienaturalne, co jest szczególnie zauważalne przy nachylonych liniach lub krzywych. Antyaliasing działa na zasadzie wygładzania krawędzi poprzez mieszanie kolorów pikseli na granicy obiektu z kolorami pikseli tła, co tworzy iluzję płynności. Przykładem zastosowania antyaliasingu jest grafika komputerowa w grach, gdzie zapewnia on bardziej realistyczny obraz, a także przy renderowaniu grafik wektorowych do rastrowych. W standardach branżowych, takich jak OpenGL i DirectX, zastosowanie antyaliasingu jest zalecane, aby poprawić jakość wizualną i doświadczenia użytkowników. Zastosowanie technik takich jak MSAA (Multisample Anti-Aliasing) lub FXAA (Fast Approximate Anti-Aliasing) jest powszechną praktyką w nowoczesnych aplikacjach graficznych.