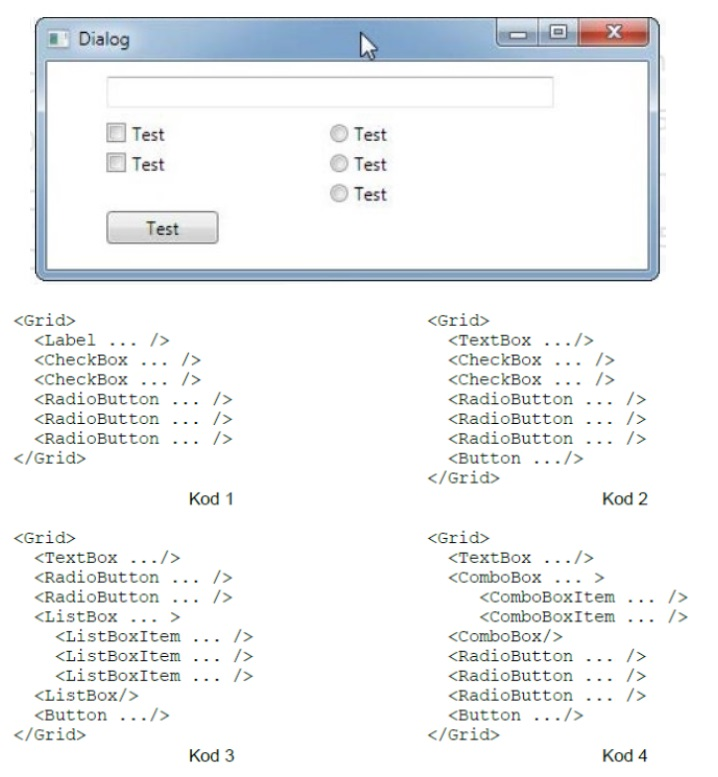
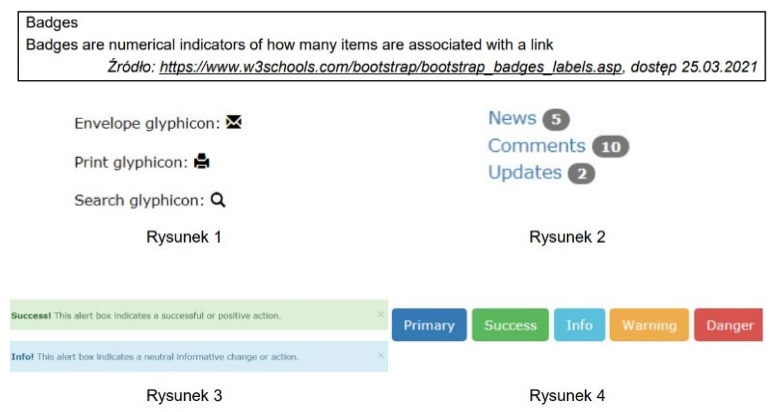
Pytanie 1
Co to jest wskaźnik w języku C?
A. Funkcja do dynamicznej alokacji pamięci
B. Zmienna przechowująca wartość logiczną
C. Zmienna przechowująca adres pamięci
D. Typ danych do zapisywania tekstów
Wskaźnik w języku C to zmienna przechowująca adres pamięci innej zmiennej. Umożliwia bezpośrednią manipulację pamięcią, co czyni wskaźniki niezwykle potężnym narzędziem w programowaniu niskopoziomowym. Dzięki wskaźnikom można dynamicznie alokować pamięć, przekazywać duże struktury danych do funkcji bez ich kopiowania oraz implementować struktury danych, takie jak listy, drzewa czy grafy. Wskaźniki umożliwiają także iterowanie po tablicach i efektywne zarządzanie zasobami systemowymi, co czyni je kluczowym elementem w programowaniu systemowym.