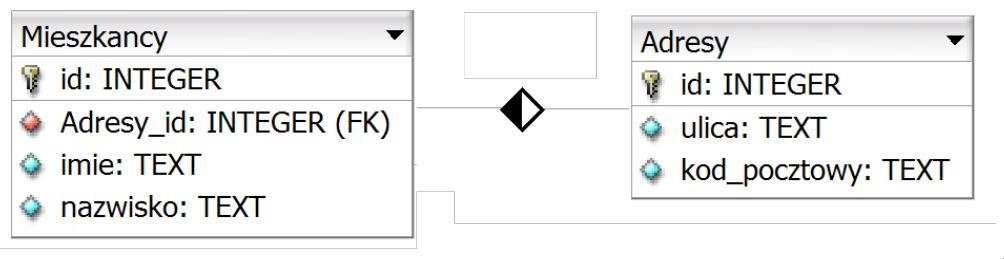
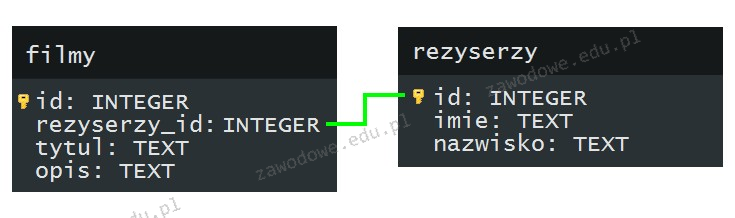
Pytanie 1
Jakie dane zostaną wyświetlone po wykonaniu podanych poleceń?
bool gotowe = true; cout << gotowe;
A. nie
B. 0
C. tak
D. 1
W języku C++ zmienne typu bool mogą przyjmować jedynie dwie wartości: true i false. Gdy zmienna typu bool zostanie wypisana przy użyciu standardowego strumienia wyjściowego cout, to domyślnie wartości true i false są konwertowane na liczby całkowite 1 i 0 odpowiednio. Dlatego w zaprezentowanym fragmencie kodu zmiennej gotowe przypisano wartość true, a następnie jej zawartość została wypisana przy użyciu cout. Wynikiem tego działania będzie wyświetlenie liczby 1 na ekranie. Jest to zgodne z domyślnym zachowaniem cout w przypadku zmiennych typu bool w C++. Aby modyfikować to zachowanie i bezpośrednio wypisywać słowa true lub false, można użyć specjalnej flagi boolalpha, która sprawia, że wartości logiczne są reprezentowane jako tekst. Jednak w podanym przykładzie nie użyto tej flagi, co prowadzi do wypisania wartości liczbowej. Takie podejście jest powszechne w wielu aplikacjach, gdzie wartości logiczne muszą być szybko zamieniane na wartości liczbowe, na przykład w obliczeniach binarnych czy przy operacjach bitowych. Poprawne zrozumienie tego mechanizmu jest kluczowe dla programistów tworzących efektywne i czytelne aplikacje w C++.