Pytanie 1
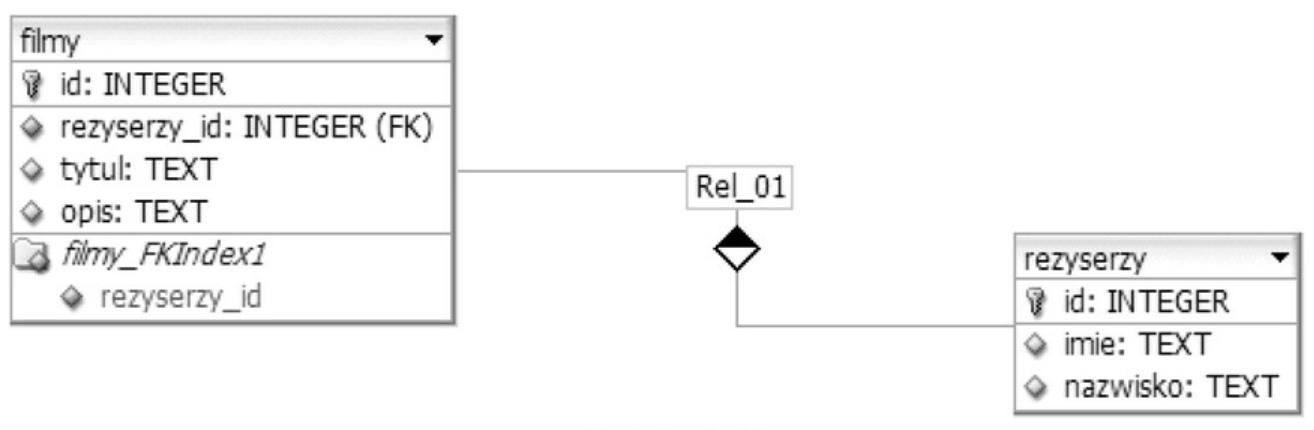
W tabeli klienci znajduje się pole status, które może przyjmować wartości: Zwykły, Złoty, Platynowy. Z uwagi na to, że dane klientów o statusie Platynowy są przetwarzane najczęściej, konieczne jest utworzenie wirtualnej tabeli (widoku), która będzie zawierała wyłącznie te informacje. W tym celu można użyć kwerendy
A. CREATE VIEW KlienciPlatyna AS SELECT * FROM klienci WHERE status = "Platynowy"
B. CREATE VIEW KlienciPlatyna FROM klienci WHERE status = "Platynowy"
C. CREATE VIEW KlienciPlatyna AS SELECT status FROM klienci WHERE "Platynowy"
D. CREATE VIEW KlienciPlatyna AS klient WHERE status = "Platynowy"
Wszystkie inne odpowiedzi zawierają błędy w składni SQL lub koncepcjach dotyczących tworzenia widoków. Odpowiedź pierwsza, sugerując 'CREATE VIEW KlienciPlatyna AS klient WHERE status = "Platynowy";', jest niepoprawna, ponieważ nie podaje poprawnej struktury zapytania. W SQL nie używa się słowa kluczowego 'client' w takim kontekście. Odpowiedź druga, 'CREATE VIEW KlienciPlatyna FROM klienci WHERE status = "Platynowy";', wykorzystuje słowo kluczowe 'FROM', które nie jest obsługiwane w definicji widoków; zamiast tego powinno się używać 'AS SELECT'. Odpowiedź trzecia, 'CREATE VIEW KlienciPlatyna AS SELECT status FROM klienci WHERE "Platynowy";', także nie jest poprawna, ponieważ nie zawiera pełnej definicji warunku filtracji, a zamiast tego próbuję zastosować wartość bez kontekstu, co prowadzi do błędnych wyników. W SQL każdy element zapytania ma swoje miejsce i funkcje, a niepoprawna konstrukcja może skutkować błędami lub nieprzewidywalnymi rezultatami. W praktyce ważne jest, aby zrozumieć, jak budować zapytania w sposób zgodny z gramatyką języka SQL i jak optymalizować je dla lepszej wydajności. Prawidłowe zrozumienie struktury zapytań jest kluczowe w pracy z bazami danych.