Pytanie 1
W zaprezentowanym schemacie bazy danych o nazwie biblioteka, składniki: czytelnik, wypożyczenie oraz książka są
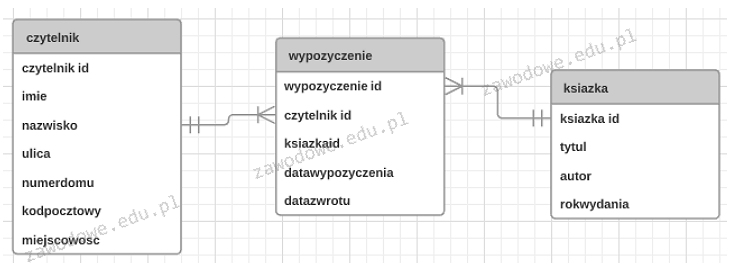
A. encjami
B. polami
C. krotkami
D. atrybutami
W kontekście modelowania danych w relacyjnych bazach danych istotne jest rozróżnienie między encjami a innymi pojęciami. Pola w bazach danych zazwyczaj odnoszą się do pojedynczych jednostek danych w obrębie kolumn tabeli reprezentujących atrybuty encji. Atrybuty to cechy opisujące encje takie jak imię czy nazwisko w przypadku encji czytelnik. Natomiast krotki często określają pojedynczy rekord czyli wiersz w tabeli który jest instancją encji. Błędne jest przypisywanie czytelnik wypozyczenie i ksiazka do kategorii pól ponieważ w modelowaniu danych pola są najmniejszymi jednostkami danych które nie reprezentują obiektów realnego świata lecz ich właściwości. Podobnie błędem jest klasyfikowanie ich jako atrybuty ponieważ atrybuty opisują encje a nie są nimi. Traktowanie tych elementów jako krotek również jest nieprawidłowe gdyż krotki to konkretne instancje danych a nie typy obiektów które chcemy modelować. Typowy błąd myślowy polega na myleniu poziomu abstrakcji czyli traktowaniu encji które są wysokopoziomowymi konceptami jak atrybuty czy krotki które są bardziej szczegółowymi jednostkami w strukturze danych. Zrozumienie tych różnic jest kluczowe dla efektywnego projektowania i implementacji baz danych oraz uniknięcia problemów związanych z redundancją czy nieefektywnością w przetwarzaniu informacji
