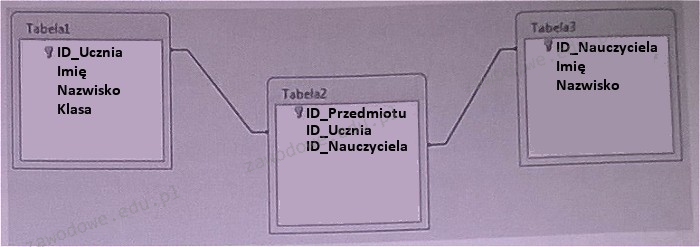
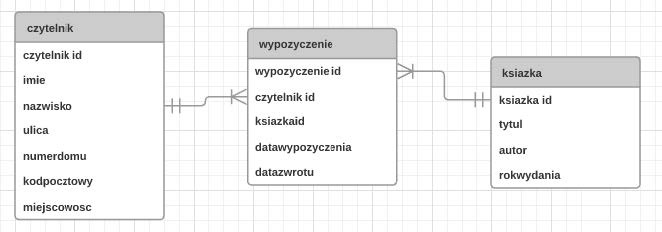
Pytanie 1
W celu modyfikacji danych w bazie danych można wykorzystać
A. formularzem
B. raportem
C. filtrowaniem
D. kwerendą SELECT
Formularz jest kluczowym narzędziem do edytowania danych w bazach danych, ponieważ umożliwia użytkownikom interakcję z danymi w sposób przyjazny i zrozumiały. Stosując formularze, można łatwo wprowadzać, modyfikować i usuwać informacje w bazie, co jest szczególnie ważne w aplikacjach typu CRUD (Create, Read, Update, Delete). W kontekście baz danych, formularze są często zintegrowane z systemami zarządzania bazami danych (DBMS), co pozwala na walidację danych wprowadzanych przez użytkowników i zabezpieczenie przed błędami. Przykładem zastosowania formularzy może być system zarządzania klientami, gdzie pracownik wprowadza dane klientów za pomocą formularza, co automatycznie aktualizuje odpowiednie tabele w bazie danych. Właściwe projektowanie formularzy uwzględnia zasady UX/UI, co zwiększa efektywność użytkowników i zmniejsza ryzyko pomyłek. Ponadto, formularze mogą być wspierane przez zaawansowane technologie, takie jak AJAX, które umożliwiają dynamiczne aktualizacje danych bez konieczności przeładowania strony.