Pytanie 1
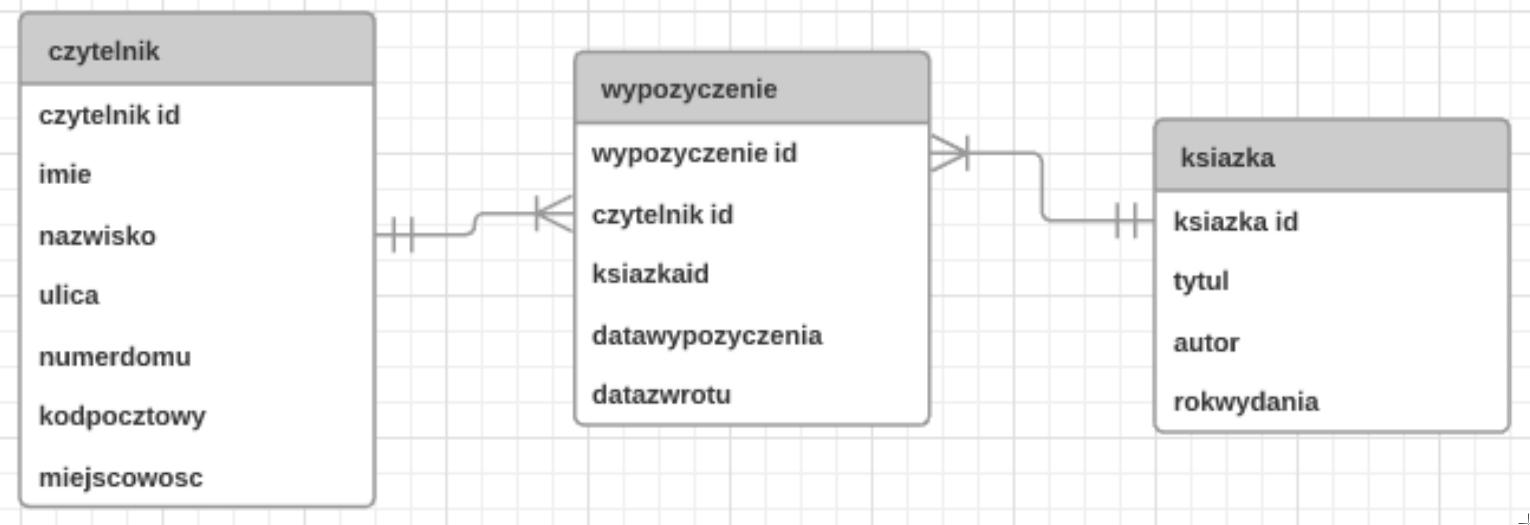
Fragment kodu SQL wskazuje, że klucz obcy
… FOREIGN KEY (imie) REFERENCES obiekty (imiona) …
A. jest odniesieniem do siebie samego
B. wiąże się z kolumną imiona
C. jest przypisany do kolumny obiekty
D. znajduje się w tabeli obiekty
Odpowiedź wskazująca, że klucz obcy łączy się z kolumną 'imiona' jest prawidłowa, ponieważ definicja klucza obcego w SQL stanowi, że odwołuje się on do kolumny w innej tabeli, w tym przypadku do kolumny 'imiona' w tabeli 'obiekty'. Klucz obcy jest używany do ustanowienia relacji między dwiema tabelami, co poprawia integralność danych i umożliwia tworzenie bardziej złożonych zapytań. Na przykład, jeśli mamy tabelę 'uczniowie' z kolumną 'imie', a tabela 'obiekty' zawiera kolumnę 'imiona' jako klucz podstawowy, to możemy użyć klucza obcego, aby zapewnić, że każde imię w tabeli 'uczniowie' odnosi się do istniejącego rekordu w tabeli 'obiekty'. Dobrą praktyką jest zawsze stosowanie kluczy obcych w celu minimalizacji błędów danych i zapewnienia ich spójności. Użycie kluczy obcych jest zgodne z zasadami normalizacji baz danych, które dążą do eliminacji redundancji i poprawy organizacji danych.