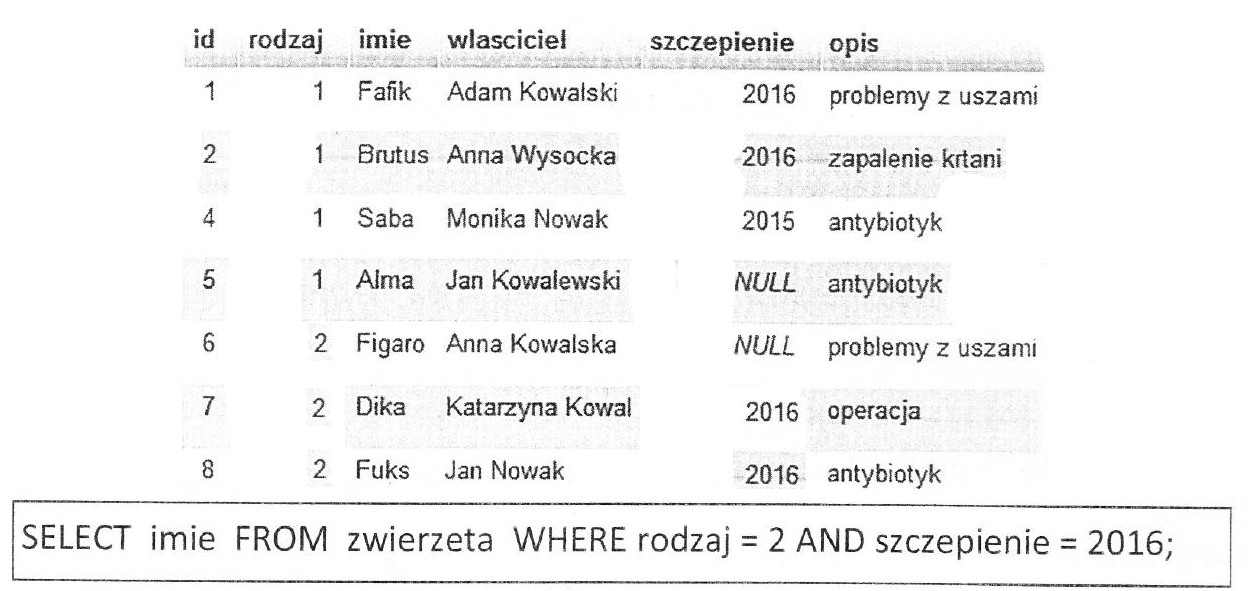
Pytanie 1
Jak nazywa się metoda udostępniania bazy danych w programie Microsoft Access, która dotyczy wszystkich obiektów bazy umieszczonych na dysku sieciowym i wykorzystywanych jednocześnie przez kilku użytkowników?
A. serwera bazy danych
B. folderu sieciowego
C. dzielonej bazy danych
D. witryny programu SharePoint
Odpowiedzi, które wskazują na "serwera bazy danych", "dzielonej bazy danych" lub "witryny programu SharePoint", nie są adekwatne w kontekście udostępniania bazy danych w Microsoft Access. Serwer bazy danych to złożony system, który zarządza dużymi zbiorami danych oraz zapewnia ich integralność i bezpieczeństwo, jednak w przypadku Microsoft Access, który jest narzędziem bazodanowym bardziej skomplikowanym niż prostsze rozwiązania, udostępnianie odbywa się głównie za pośrednictwem folderów sieciowych. Dzielona baza danych oznacza, że baza danych jest podzielona na dwie części: jedną na serwerze (backend) i drugą lokalnie na komputerach użytkowników (frontend). Pomimo że ta konstrukcja może być stosowana do zwiększenia wydajności, nie odnosi się bezpośrednio do koncepcji folderu sieciowego jako metody udostępniania. Witryna programu SharePoint jest platformą do współpracy, która pozwala na zarządzanie dokumentami i danymi w chmurze, ale nie jest bezpośrednio związana z mechanizmem udostępniania bazy danych w Microsoft Access. Zrozumienie różnic między tymi podejściami jest kluczowe, ponieważ często prowadzi to do mylnych wniosków dotyczących rozwiązań technologicznych oraz ich zastosowania w praktyce. W kontekście Access, praktyka umieszczania bazy danych w folderze sieciowym jest standardem branżowym, który zwiększa dostępność i ułatwia współpracę w zespole.