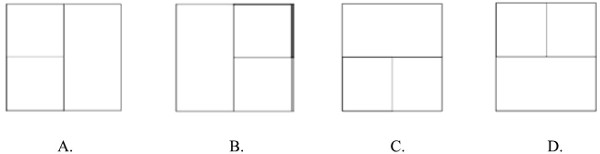
Pytanie 1
Dla celu strony internetowej stworzono grafikę rysunek.jpg o wymiarach: szerokość 200 px, wysokość 100 px. Aby zaprezentować tę grafikę jako miniaturę – pomniejszoną z zachowaniem proporcji, można użyć znacznika
A. <img src="/rysunek.png">
B. <img src="/rysunek.png" style="width: 50px">
C. <img src="/rysunek.png" style="width: 25px; height:25px;">
D. <img src="/rysunek.png" style="width: 25px; height:50px;">
Wybór innych opcji, takich jak <img src="/rysunek.png" style="width: 25px; height:50px;"> czy <img src="/rysunek.png" style="width: 25px; height:25px;"> prowadzi do nieproporcjonalnego wyświetlenia obrazu, co skutkuje jego zniekształceniem. Ustalenie zarówno szerokości, jak i wysokości w stylach CSS sprawia, że obrazek jest zmuszony do dopasowania się do tych wymiarów, co narusza jego naturalne proporcje. To podejście jest niezgodne z zaleceniami dotyczącymi responsywności, które sugerują, aby ograniczać się do jednego wymiaru, co pozwala drugiemu na automatyczne dostosowanie. Typowym błędem jest przyjęcie, że podanie obu wymiarów w pikselach zawsze przyniesie optymalny efekt wizualny, co jest mylące i może prowadzić do złego doświadczenia użytkownika. Zniekształcenie obrazów nie tylko obniża estetykę strony, ale także może wpływać na jej użyteczność oraz SEO. Dobrą praktyką jest również używanie atrybutów 'alt' w znacznikach obrazów, aby poprawić dostępność i SEO, co nie zostało uwzględnione w żadnej z opcji. Warto także zauważyć, że stosowanie odpowiednich formatów obrazów i ich optymalizacja pod względem rozmiaru pliku są kluczowe dla przyspieszenia ładowania strony.