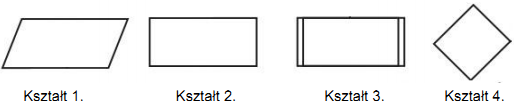
Pytanie 1
Jakie formatowanie obramowania jest zgodne ze stylem border-style: dotted solid;?

A. Formatowanie 4
B. Formatowanie 2
C. Formatowanie 1
D. Formatowanie 3
Styl obramowania w CSS pozwala na precyzyjne określenie wyglądu krawędzi elementu na stronie internetowej. W przypadku „border-style: dotted solid;” mamy do czynienia z kombinacją dwóch różnych stylów obramowania. Pierwsza wartość „dotted” odnosi się do obramowania o kropkowanej strukturze, co jest często stosowane w celu nadania lekkości i subtelności wizualnej. Druga wartość „solid” oznacza jednolite obramowanie, które jest bardziej wyraźne i stosowane, gdy wymagana jest wyraźna separacja elementów. Formatowanie 2 odpowiada właśnie temu stylowi, ponieważ przedstawia górne i dolne obramowanie jako kropkowane, a boczne jako jednolite. Takie zastosowanie jest typowe w sytuacjach, gdzie potrzebny jest kompromis między estetyką a funkcjonalnością, np. w tabelach danych, gdzie górne i dolne obramowanie może być delikatniejsze, by nie przytłaczać, a boczne wyraźne dla czytelności. Wybór właściwego stylu obramowania jest kluczowy dla użyteczności i estetyki strony, zgodnie z zasadami projektowania zorientowanego na użytkownika.