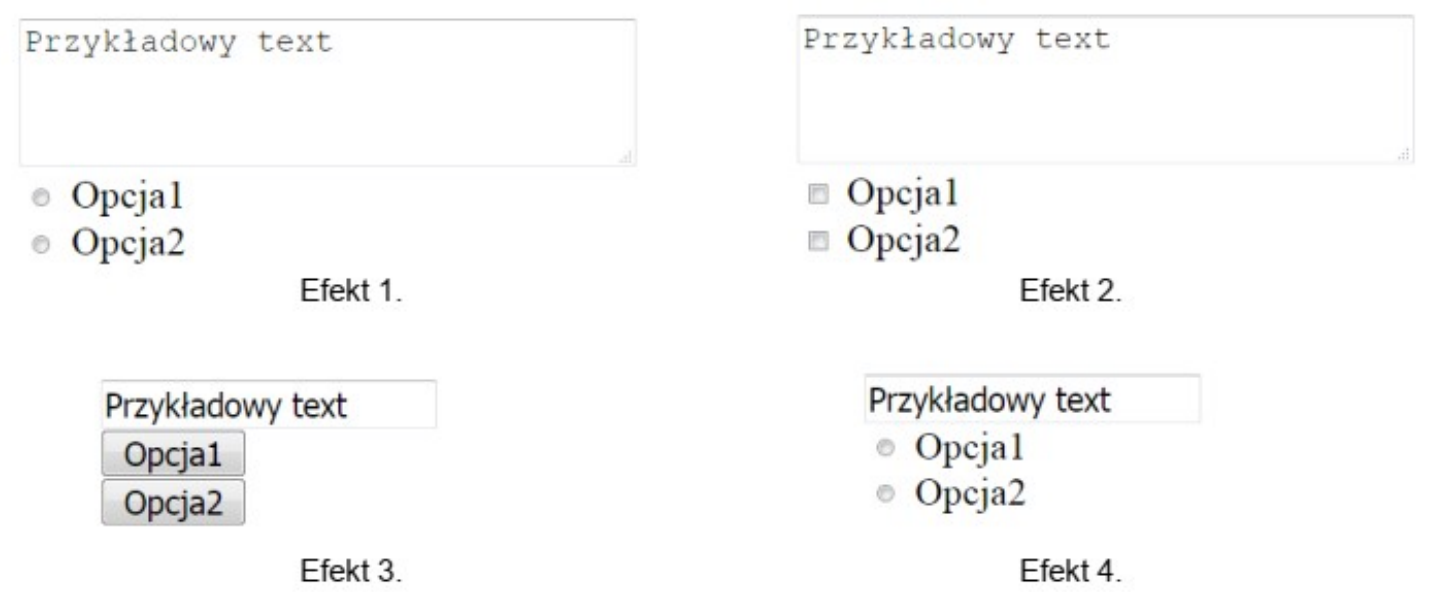
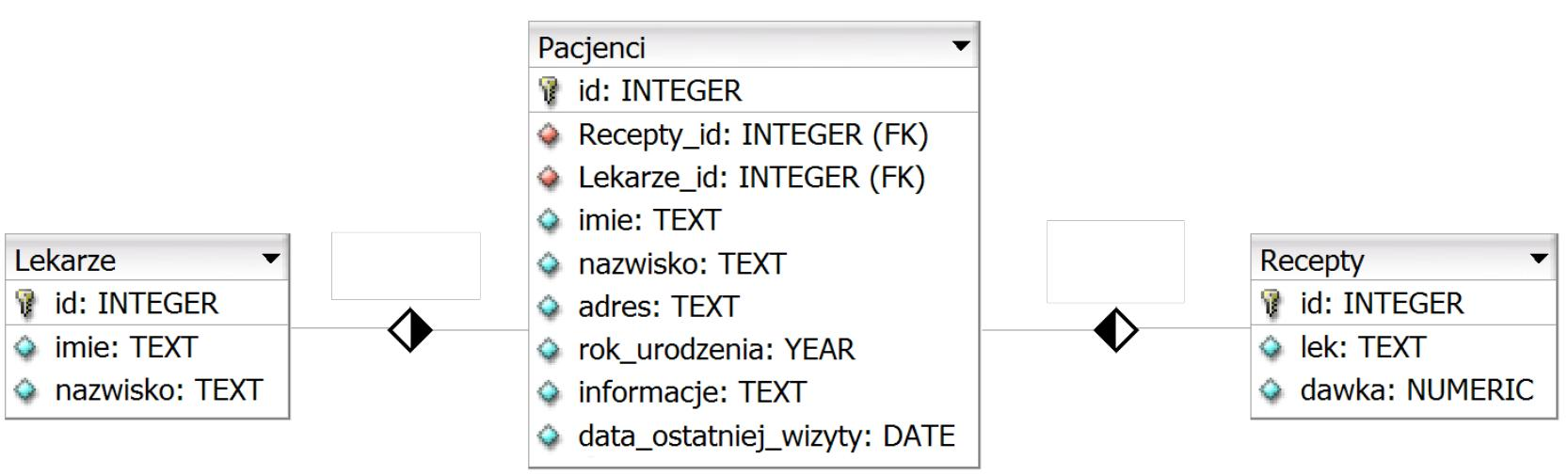
Pytanie 1
Na zaprezentowanej tabeli dotyczącej samochodów wykonano zapytanie SQL SELECT
SELECT model FROM samochody WHERE rocznik=2016;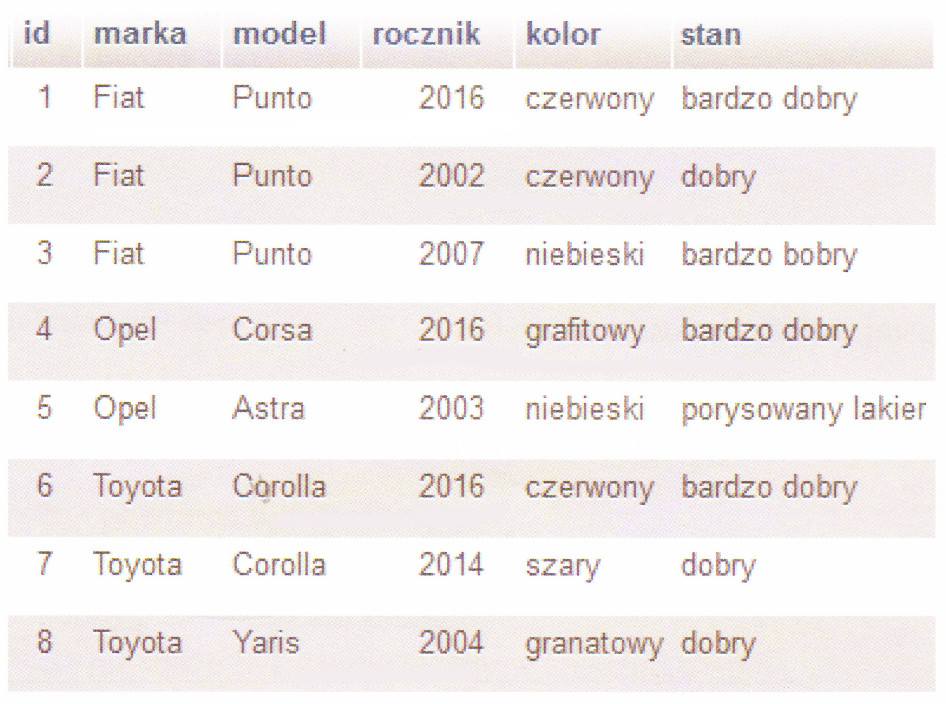
A. Punto, Corsa, Astra, Corolla, Yaris
B. Fiat, Opel, Toyota
C. Czerwony, grafitowy
D. Punto, Corsa, Corolla
Pierwsza odpowiedź Fiat, Opel, Toyota jest nieprawidłowa, bo zapytanie SQL wybiera kolumnę model, a nie marka. Marka to producent samochodu, więc to trochę mylące, ale w SQL to ważna różnica. Druga odpowiedź Czerwony, grafitowy też jest zła, bo odnosi się do koloru aut, a nie modeli. Zapytanie SQL SELECT model FROM samochody WHERE rocznik=2016 jasno pokazuje, że chodzi o modele, a nie kolory. To częsty błąd, gdy nie patrzy się na kolumnę wybraną w zapytaniu. Czwarta opcja Punto, Corsa, Astra, Corolla, Yaris ma kilka modeli, które są w porządku, ale też dodatkowe, które nie pasują do rocznika 2016. To typowe, gdy wyciąga się za daleko i zakłada więcej niż mówi zapytanie. Umiejętność dokładnego rozumienia wyników zapytań SQL jest ważna, zwłaszcza gdy analizujesz dane, bo błędna interpretacja prowadzi do złych wniosków. Dobrze jest zwracać uwagę na szczegóły, takie jak kolumny i warunki w zapytaniu, bo to kluczowe w pracy z bazami danych. Fajnie jest zrozumieć każdy element składni SQL, żeby unikać błędnych założeń i mieć pewne dane do analizy, co jest ważne w dobrym zarządzaniu danymi.